
데이터 엔지지니어링에서 가장 중요한 파트를 뽑으라면 아마 ETL 단계가 아닐까 싶습니다. 모든 분석의 결과값에 사용되는 데이터들이 ETL 및 ELT 과정을 통해 DW 내에 적재되기 때문입니다.
최근 ETL에서 ELT로 거의 바뀌는 추세라고는 하지만 여전히 ETL을 사용하는 곳들이 많고 제가 다니고 있는 조직에서도 ETL 패턴을 유지하고 있기 때문에 효율성과 비용, 확장성을 고려해서 각자 회사 상황에 맞는 방식을 선택하는 것이 현명한 선택이라는 생각이 듭니다.
이번에 ETL 개편 자료 조사를 하면서 무작정 새로운 것들을 도입하는 것보단 뿌리부터 데이터 히스토리를 파악해서 가장 효율적인 방법을 찾아나가는 게 중요하다고 생각되어 제가 조사했던 ETL과 ELT의 차이점 및 어떤 상황에 해당 패턴을 사용하는 게 맞는 것인지를 작성해 보려고 합니다. 물론 모든 과정에 정답은 없습니다. 각자 상황에 맞게 프로세스를 꾸려나가는 것이 데이터 엔지니어의 숙명인 듯합니다.... ㅜㅜ
1) ETL

Extract, Transform, Load의 약자로
데이터를 원천에서 가져오는 추출(Extract), 추출한 데이터를 원하는 형태로 가공하는 변환(Transform), 변환 후 타겟 목적지까지 저장하는 적재(Load)의 흐름으로 진행됩니다.
불필요한 데이터를 추출하지 않고 원하는 데이터만 선택적으로 추출해서 저장소를 효율적으로 다룰 수 있다는 장점이 있습니다. 워낙에 보편화된 기술이고 관련한 기술자들이 많기 때문에 이런 형식을 다룰 수 있는 엔지니어분들이 많다는 것도 하나의 장점이 될 수 있겠습니다.
하지만 이 과정을 통해서 뭘 얻고자 하느냐? 결국 우리가 원하는 건 정제되고 시각화된 리포트들입니다.
예를 들어 매일 아침마다 매장별일매출을 확인한다던지, 판매량을 본다던지 일 배치로 매일매일 확인해야 하는 데이터들을 새벽마다 대용량의 데이터를 변환시켜 처리하려면 운영상의 난이도가 올라가고 관리가 빡세다는 단점이 있습니다.
또한 이미 해당 리포트에 맞게 테이블을 만들어 적재를 해 놓았으니 리포트를 사용하는 팀에서 다른 형식으로 데이터를 뽑아달라는 요청이 왔을 때 그 형태에 맞게 또 다른 테이블을 생성해서 적재를 진행해야 한다는 게 가장 크리티컬한 단점이 아닐까 싶습니다.
저희 부서 같은 경우는 아직 ETL 형식을 사용하고 있어 마스터 테이블이라는 개념을 빌려 모든 경우의 수를 다 조합할 수 있는 원천 데이터들을 조인해서 모든 데이터가 담긴 ODS 테이블을 만들어 두었습니다. 뭐 이런 식으로도 방법을 만들 수는 있겠지만 컬럼이 200 개정도가 넘어가는 불상사가... ^^; 그 테이블을 바라보고 결국 다른 팩트 테이블을 설계해야 하는데 유지보수 측면으로도 영 이게 맞는 건지 썩 마음에 들진 않습니다. 하지만 더 효율적이고 괜찮은 방법이 생각나지 않아요 ㅠㅠㅠ 클라우드 dw를 도입할 수 있는 환경도 아니라.. 도입한다고 해도 비용 관리를 혼자 다 해야 한다는 부담감이.. 어흑
ETL에 사용되는 툴은 다음과 같습니다.
- 인포매티카 PowerCenter
- Pentaho ETL
- FiveTran, Stitch Data
- Airflow
- 다른 클라우드 서비스 (AWS Glue, etc ...)
파이브트란이나 스티치 같은 경우에는 CDC도 지원을 해 주고 SaaS형 솔루션이기 때문에 꽤나 비용이 비싼 것으로 보였습니다. ETL한 행수 별로 월 비용처리를 한다거나 그랬던 것 같고 인포매티카는 사용해보진 않았지만 한국 지사 철수로 아마 지금 당장 도입은 안 되는 걸로 알고 있습니다 ㅎ 펜타호도 마찬가지로 네이버 클라우드 기준 제일 싼 게 월 250 이더라구요. 물론 무료 버전인 CE 버전도 있습니다만 간단한 처리를 하기엔 좋지만 오류가 났을 때의 단점이 좀 있어서 상황에 맞는 스케줄러나 프레임워크를 도입하는 것이 좋겠습니다.
2) ELT

Extract, Load, Transform 의 약자로
ETL과 다르게 변환의 순서가 다릅니다. 데이터를 추출한 다음 바로 적재를 하고, 후에 변환을 하는 시스템입니다. 거의 클라우드 DW가 등장을 하면서부터 ELT의 방식이 점점 늘어나는 추세가 된 것 같습니다.
AWS로 예를 들자면 원천 데이터를 S3에 적재한 후 glue로 S3를 읽어 들여 RDB의 테이블 형태로 만들어 (glue 데이터 카탈로그의 기능) Athena 혹은 RedShift에 Load 해서 아테나와 레드시프트 안에서 Transform을 하는 방식의 시스템인 것입니다.
이러한 방식의 장점은 데이터 변환이 DW 안에서 이루어지기 때문에 변환되어서 적재가 되는 과정에 오류가 생겨서 적재가 되지 않거나 네트워크가 끊겨서 멈췄다거나 하는 그런 걱정이 하나도 없을 수가 있고, 원본 데이터를 모두 가지고 있기 때문에 필요할 때마다 빠르게 바로 가져다 원하는 형태의 분석 데이터를 만들 수 있습니다.
클라우드 DW들을 사용해 본 적이 없어서 잘 모르겠는데, 로드된 데이터 자체가 일단 원천 데이터인데 혹시 그 원천 데이터에서 데이터 오류가 발생하였다면? 그때의 오류를 어떻게 해결하고 데이터 품질 관리는 어떻게 진행해야 할지는 잘 감이 안 잡히긴 하네요...... 원천에서부터 오류가 난다면 그건 데이터 엔지니어링에서 해결할 수 없는 부분이긴 하지만 그 부분은 제외하고 분석에 활용을 하는 건지...... 는 갑자기 궁금해진 부분이네요.
- 그렇다면 언제 ELT를 사용해야 하는지?
- 대용량, 다양한 데이터를 보유했을 때 -> ELT는 정형 데이터와 비정형 데이터를 모두 아우를 수 있습니다.
- 빠르게 처리해야 할 때 -> 스트리밍 데이터를 필요로 할 때 ELT로 처리하는 것이 효율적일 수 있습니다.
- 어떻게 분석해야 할지는 모르겠는데 일단 데이터 저장은 필요해! -> 저장 스토리지 비용이 쿼리 한번 돌리는 것보다 싸기 때문에 오히려 먼저 적재해놓고 나중에 분석하는 게 더 효율적이라고 판단할 수도 있겠네요..
ELT에서 살펴봐야 할 프레임워크 및 클라우드 DW, 옵션들은 다음과 같습니다.
- AWS RedShift
- AWS Athena
- Snowflake
- GCP BigQuery
- Apache Hive
- Apache Presto
- Apache Iceberg
- Apache Spark
레드시프트는 다들 비용이 부담이 돼서 거의 아테나로 넘어가는 걸 권장한다고 어디서 들은 것 같은데...... 둘 다 사용을 해보질 않았으니 저는 첨언할 게 없네요 ㅠ 개인적으로 데이터 엔지니어링 쪽은 GCP가 정말 효율적으로 잘 사용할 수 있을 것 같은데 저희 회사는 또 AWS 서버 기반이라 빅쿼리 도입한다고 하면 설득도 전에 이미 문전박대가 되지 않을까 싶네요..
클라우드 DW가 우리 조직에게 필요한가를 생각해 봤을 때 저는 이 정도의 질문을 스스로에게 남겼습니다
- 현재 조직의 리소스가 어떻게 되는가?
- RDS Oracle 계약으로 사용 중 -> DW도 오라클에 단독 dw 서버 만들어 적재 중
- ETL에 드는 비용은 없음. 펜타호 무료 버전 사용 중. 하지만 DB의 과부하, 트래픽 비용, 원인을 찾을 수 없는 디비락 ㅜ, 시간소요, 네트워크 전송 실패 문제로 어떻게든 툴을 바꾸거나 데이터 파이프라인 개선이 필요한 상황
- 이미 나가고 있을 돈은 다 나가고 있다. 도입을 하면 추가 비용만 발생할 텐데 여기서 비용으로 승부를 볼 수 있을까?
- BI 툴도 라이센스 계약으로 사용 중이라 ETL과 DW단만 지지고 볶으면 된다.
=> 원천데이터를 ODS에 적재하는 부분을 감소시키자. 현재 RDS의 용량을 원천데이터에서 ODS로 그대로 복사해서 사용하고 있기 때문에 이 과정을 S3에 저장시키고 (비용 감소) Athena로 분석 테이블들을 생성시키면 일도 간편해지고 관리에도 용이할 것으로 보임
정도로 결론을 내렸지만 어떻게 진정성 있게 설득을 할지가 지금 현재 저의 고민인 것 같습니다. 그래도 글을 쓰면서도 조금 정리가 되긴 되어서 스스로에게도 도움이 되긴 했네요.
관련 자료를 찾아 보다 사례를 통한 아키텍처가 있어 참고해 보면 좋을 것 같아 첨부합니다.
https://azureplatform.tistory.com/18
ETL과 ELT (데이터 프로세싱 아키텍처/가공 처리 과정)
오늘도 Azure로운 Power Platform :D 데이터 엔지니어링이나 데이터 사이언티스트 직업을 가지고 계신 분들은 ETL과 ELT라는 용어에 익숙하실겁니다. 주로 데이터 프로세싱 아키텍처를 짤때 많이 등장
azureplatform.tistory.com
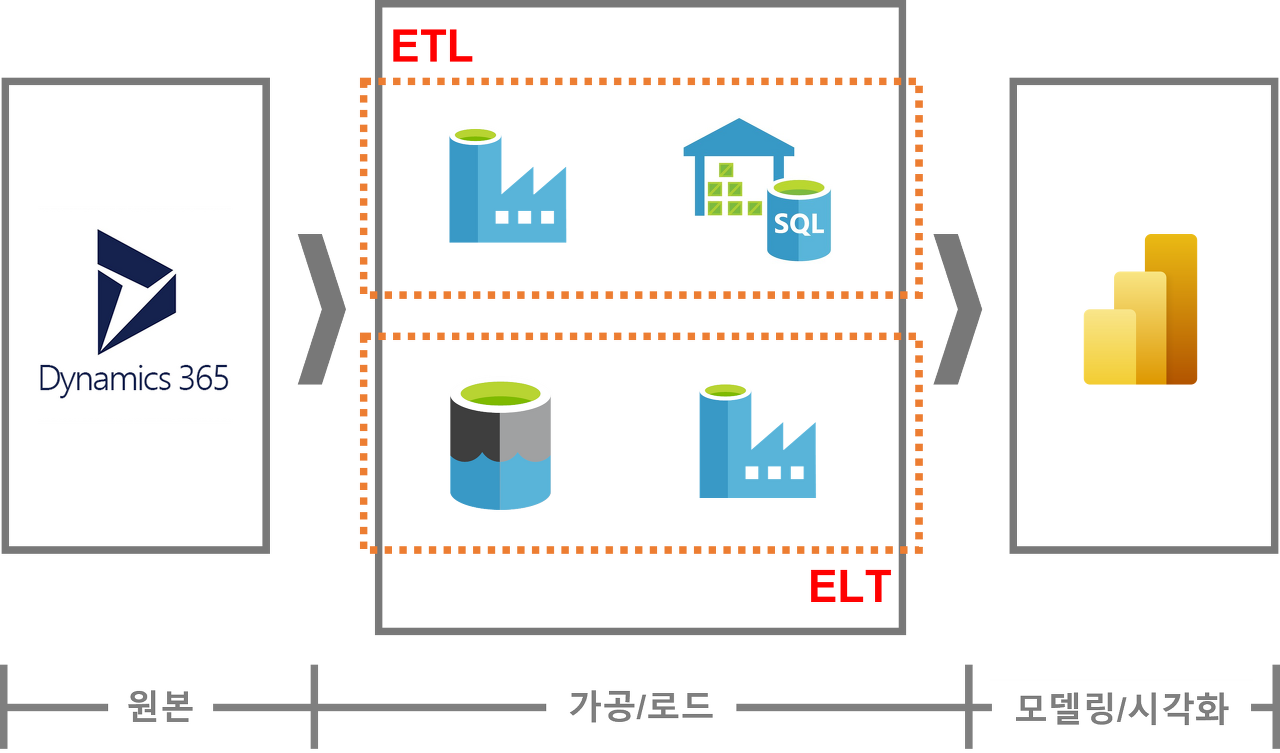
ERP 시스템의 고객사별 매출 데이터를 BI 보고서로 만들고자 할 때
ETL 사용 시)
1. 시각화 보고서를 개발하기 위한 데이터 모델 설계
2. 고객 및 매출 관련 데이터를 가져와 설계한 모델에 맞춰 가공한 뒤 로드
3. 로드한 데이터로 실제 모델링 진행 후 시각화 보고서 개발
** 고려사항
1) 보고서 내용이 바뀌거나 추가되면 데이터를 그에 맞춰 다시 가공하고 다시 로드해야 함. 가공 단계부터 다시 시작해야 됨
2) 실제 보고서를 만들 때, 가공해서 로드한 모든 데이터를 사용하지 않게 될 수도 있음. 낭비된 비용 발생
3) 가공 전 데이터에 접근하여 다른 가공을 해봐야 하는 상황이 생길 수 있음. 이 경우, 가공 전 데이터를 원본에서부터 다시 끌고 와야 함. ==> 여기서 그 원본 데이터가 어디에 있는지부터 또 찾아야 함. 그리고 ETL 작업을 다시 하고 원천 데이터 가져오는 ETL, 가져와서 가공하는 ETL을 또 만들어야 됨
ELT 사용 시)
1. 시각화 보고서를 개발하기 위한 데이터 모델 설계
2. 고객 및 매출 관련 데이터를 가져와 우선 전부 로드
3. 1에서 설계한 모델에 맞춰 로드된 데이터 중 필요한 데이터만 가져와 가공
4. 가공한 데이터로 실제 모델링 및 시각화 보고서 개발 진행
** 고려사항
1) 보고서 내용이 바뀌거나 추가되면 로드된 데이터 내에서부터 가공하면 됨. 로드 이전에 가공하는 게 아니라 로드 후 가공이라 비용과 시간이 줄어듦.
2) 실제 보고서를 만들 때, 로드되어 있는 데이터 중 필요한 데이터만 가져와 모델링 및 시각화를 진행함. 낭비되는 비용이 발생하지 않음.
3) 가공 전 데이터에 접근하여 다른 가공을 해봐야 하는 상황이 생길 수 있음. 이 경우 이미 로드되어 있는 데이터만 확인하면 됨.
그렇다면 내가 지금 ODS에 원천에서 들고 올 수 있는 데이터 다 들고 와서 200개 컬럼이 들어있는 테이블은 과연 불필요한 낭비 비용인 ETL인 것인가 우선 고객 매출 관련 데이터를 전부 로드한 ELT인 것인가...... 갑자기 또 의문점이 들었네요. RDS가 비싸니까 낭비라고 보면 되는 걸까요? 스토리지 비용으로? 그렇다면 그 스토리지를 없애고 S3로 간다면 비용이 절약되는 건지? 또 고민이 시작되었습니다... 클라우드 DW만 아니다 뿐이지 일단 모두 다 로드해서 적재해놓긴 했는데 실시간 쿼리 분석이 안 된다는 점에서 패착이 있긴 하지만 또 실시간 분석 리포트를 진행하고 있는 건 아니라... ELT로 가게 된다면 실시간 리포트로 확인할 수 있다는 점에서 확장성이 있기는 하네요.
어찌됐든 상황에 따른 최대한의 좋은 방안은 설계한 사람이 생각하기 나름인 것 같습니다.
확실히 현업 관련 사례를 보면서 차이점을 보니 어떤 상황에서 비용을 더 아낄 수 있고 운영하기에도 용이한지 한눈에 파악이 되는 것 같습니다. 같은 고민을 하시는 분들이 있다면 조금이나마 도움이 되셨으면 좋겠습니다.
레퍼런스
'Develop > DATA Engineering' 카테고리의 다른 글
| 대용량 데이터를 전송하는 방법(1) - Message Queue (0) | 2024.01.07 |
|---|---|
| [빅데이터를 지탱하는 기술] 01 - 1주차 스터디 (0) | 2022.09.14 |
| Airflow (0) | 2022.05.13 |