

시작하며
[글또xUdemy] AWS Certified Solutions Architect Associate 시험합격! 강의 후기 에 이어 두 번째로 선택한 강의는 Spark 관련 강의였는데요. 데이터 엔지니어링과 데이터 인프라 구축 니즈가 올라가면서 데이터를 다루는 조직들에게는 Spark가 거의 필수 요소가 되었습니다. 지금 제가 속한 조직은 Spark를 사용하지 않고 그대로 데이터베이스 서버를 이용해서 리소스를 사용하고 있는데요, 데이터 파이프라인을 새롭게 구축하면서 Spark 에 관한 내부 구조와 관련 문법들 이 엔진이 대용량 처리에 왜 유리한지에 대해 하나하나 짚어보고자 해당 강의를 선택하게 되었습니다. 아직 다 보진 않았지만 내부 구조에 대해서 그렇게 자세하게 알려주진 않고 실무에 어떻게 쓰이는지 실습이 주로 이루어진 강의입니다.
강의 소개
【한글자막】 Apache Spark 와 Python으로 빅 데이터 다루기
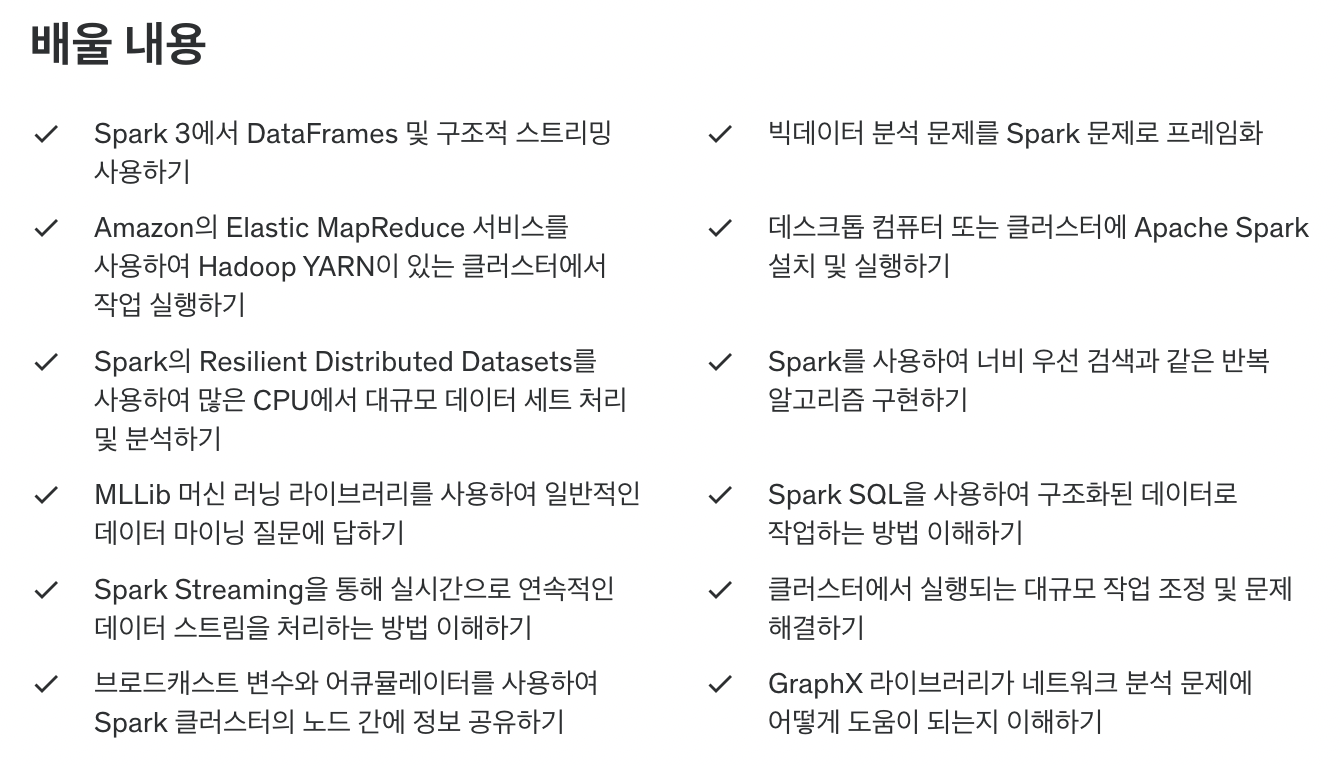
이 강의에서 다루는 내용은 다음과 같습니다. 저는 데이터 마이닝까지는 필요가 없어서 실시간으로 처리되는 데이터 스트림과 Spark SQL, 클러스터와 노드 위에서 이루어지는 개념과 같은 것들에 중점을 맞추어서 강의를 들었습니다.
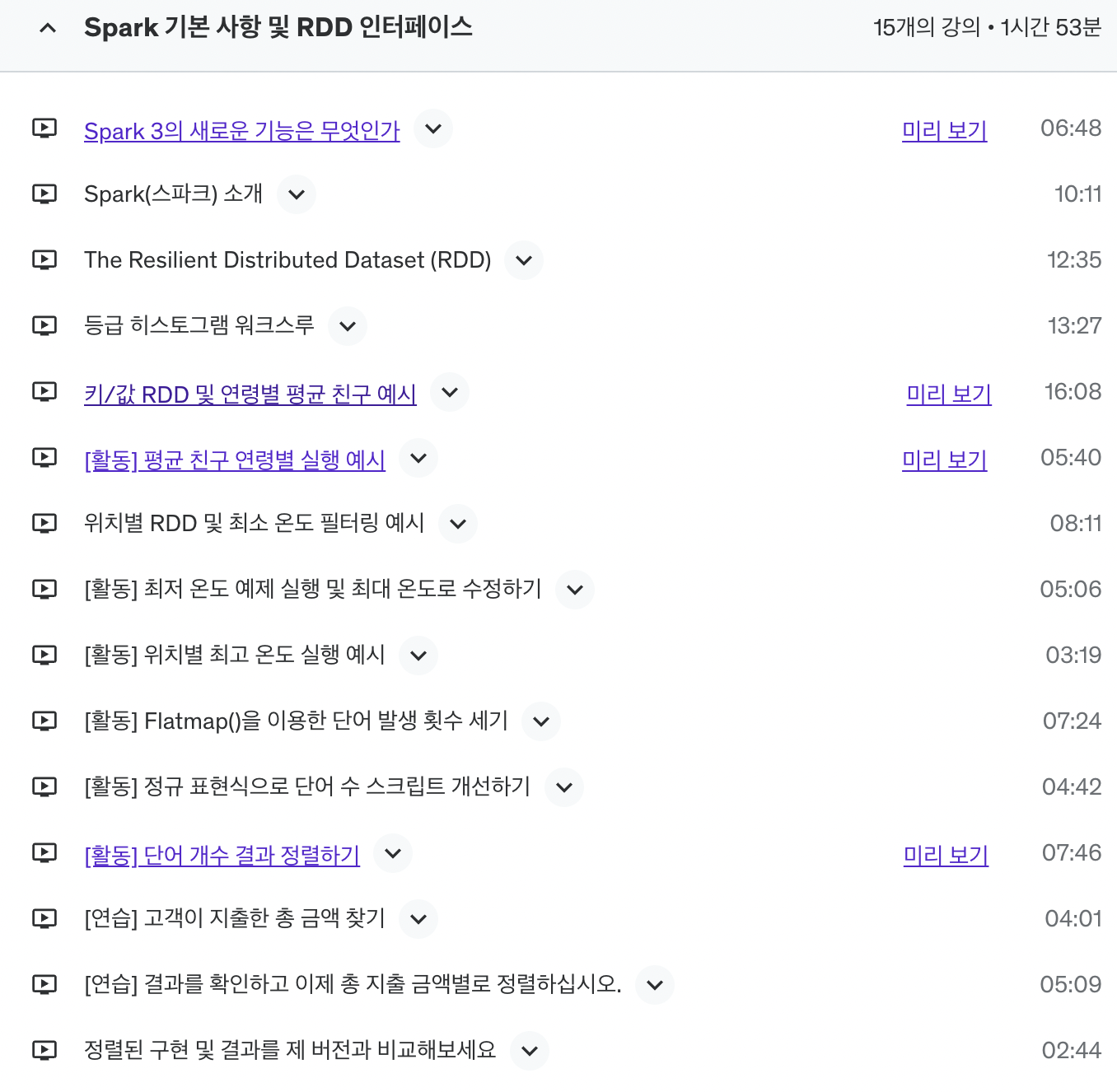

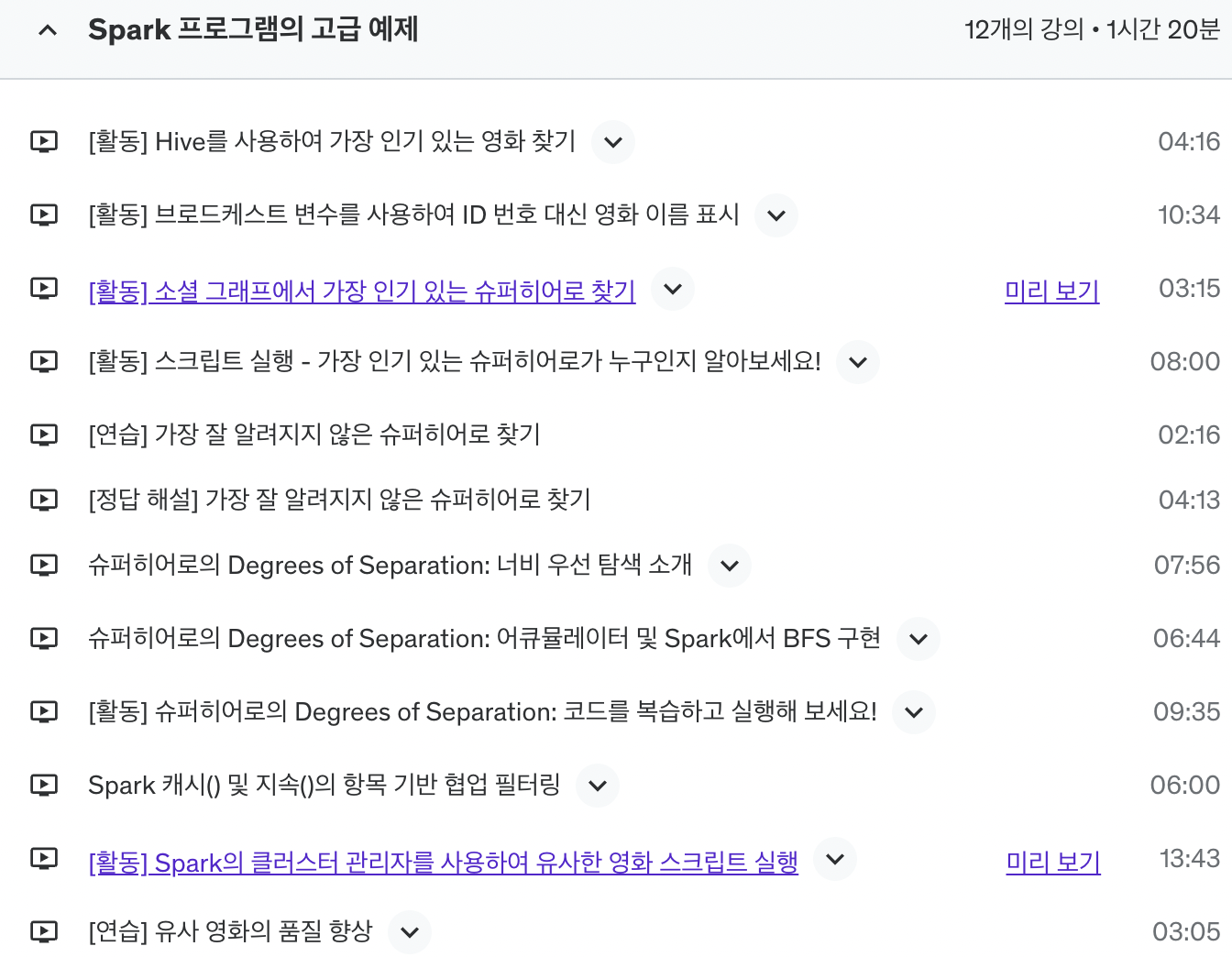


강의 목차는 다음과 같습니다.
Spark의 데이터 구조인 RDD, DataFrames, DataSets에 대해서 개념을 정립하고 해당 구조에 대해 이해할 수 있게 실습을 진행합니다. 추가로 Spark ML도 다루고 있으니 머신러닝 분석하시려는 분들에게도 도움이 될 것 같네요
이런 분에겐 추천해요
- Spark가 완전 처음이다
- 너무 자세하게는 말고 간단하게 큰 그림으로 훑어 보고 싶다
- 책보다는 강의 보면서 코드를 따라치면서 배우는 게 성향에 맞다
- 당장 실무에서 어떻게 사용할 수 있는지 알고 싶다
이런 분한테는 비추...
- Spark에 대해서 어느 정도 알고 사용 중인데 레벨업을 하고 싶다
- Spark를 활용한 응용 작업에 대해서 자세하게 알고 싶다
- 클라우드 환경에서 Spark 엔진이 내장된 서비스를 이미 사용 중이다
- 파이썬을 배운 적이 없다
확실히 실습 위주가 많은 강의입니다. 생각보다 이론에 대한 주제는 짚어주지 않고 이미 Spark를 도입해서 사용 중이신 분들에게는 맞지 않을 것 같다는 생각이 들더라고요. 저는 실무에서 Spark를 사용해 본 적이 없기에 어느 정도 개념 잡으면서 코드 따라 쳐보면서 실습하니까 대충 플로우가 어떻게 흘러가는지는 감이 잡히긴 했습니다. 심화 내용을 바라신다면 이 강의는 안 맞을 수 있어요!
강의 전반적인 내용
- 몇 년 전에 촬영한 내용이라 버전이 안 맞으면 어쩌지 싶었는데 버전에 대한 이슈들은 따로 체크를 해서 수정본을 업로드해 두셨습니다.
- 로컬 환경에서 Spark를 설치하여 실습을 하기 때문에 초반 설치 때문에 애를 많이 먹으실 수도 있습니다...... 강의 내용과는 좀 다를 수 있어서 저도 구글링을 하면서 설치를 하고 실습을 진행했습니다.
- AWS EMR도 활용하는 강의가 나오는데, 이 부분은 따로 진행하지는 않았습니다.
- PPT에 자료를 띄워 수업을 진행하시는데... 하늘색 화면에 글자만 계속 있어서 전체적으로 강의에 집중이 된다는 느낌은 안 들더라구요 ㅋㅋㅋ 그래도 차근차근 잘 따라가신다면 얻어가는 게 있으실 겁니다.
- 실습 내용에 따른 코드 흐름이 전부입니다. 전체적인 그림을 보기에는 최고인 것 같고 저같이 Spark가 처음인 사람들에게는 가볍게 개념 정리하기에는 좋은 것 같아요.
총평
장점과 단점은 위에서 언급을 했으니 간단한 총평만 진행하고 글을 마무리하겠습니다.
회사에서 이번에 데이터 파이프라인 개편 작업을 진행하면서 많은 자료조사들을 시작했었습니다. 데이터 엔지니어링에 필요한 로드맵을 정리해 둔 사이트가 있었는데요. 개인적으로 그 로드맵을 봤을 때는 내가 어떤 기술과 어떤 개념을 가져야 엔지니어로써의 자질을 쌓을 수 있을지 고민했다면 지금은 어떤 파이프라인과 로직, 기술들이 회사 프로세스에 맞을지 고민하는 과정을 거치면서 다뱡면의 상황을 고려해 적절한 기술을 사용하는 것에 대해서 판단을 할 수 있는 능력이 점차 쌓여가고 있는 것 같은 느낌을 받았습니다.
자료 조사를 하면서 항상 봤던 문구는 회사에 Spark를 사용하고 있지 않다면 도입을 하려는 시도는 해 보라는 말을 정말 많이 봤었는데요. 그걸 보면서 무작정 다른 회사는 다 spark 쓰고 있고 추후 이직을 위해서라도 spark를 나도 써 봐야 하는 거 아닐까? 라는 생각을 했지만 막상 도입을 위해 사유를 쓰려니 어떠한 사유로 spark를 써야 합니다 라고 설득 자료를 만들지를 못 하겠더라구요. 이유를 생각해 보니 저 자체가 Spark에 대한 개념 자체를 모르고 있기 때문에 무작정 도입만 고려하고 있었던 것이었습니다.
이번 강의를 들으면서 확실하게 얻어간 게 있는데요 ㅎㅎ 강의를 듣고 실습해 보면서 데이터 흐름에 대한 이해가 되었고, 현재 우리 회사의 프로세스에서 어떤 부분에 Spark 엔진을 사용하면 효율적일지에 대한 응용이 가능해졌다는 것에 대해 큰 도움이 되었다고 생각합니다.
강의에 대해서 궁금한 점이 있다면 언제든 댓글 남겨 주시면 답변 드리겠습니다. 감사합니다.
'Develop > 강의' 카테고리의 다른 글
| [글또xUdemy] AWS Certified Solutions Architect Associate 시험합격! 강의 후기 (0) | 2024.03.31 |
|---|