데이터 직무로 제대로 입사를 하고 난 이후로는 대외활동에 참여를 많이 하려고 노력 중인데, 운 좋게 한데모 밋업에 당첨이 되어 반차를 쓰고 서울로 올라갔다 ㅋㅋ
원래는 미팅이 있어서 4월 1-2 서울에 있을 예정이었는데 일자가 바뀌어서 어쩌다 보니 진짜 한데모만 보러 서울 올라간 사람됨
참여 폼에는 미팅 일자가 하필 겹쳐서 한데모 참여하면 너무 좋을 것 같다고 써서 그래서 붙여 주신 것 같았는데 어떻게 일정이 그렇게 되어 버렸다..
모임은 당근 마켓에서 장소를 제공해 주신다 하여 내가 당근 사옥을 또 언제 가 보겠어... 하는 마음으로 (언젠가 일원으로 함께 하고 싶다 ㅜ) 설레는 마음 반 긴장 반으로 도착했습니다
유명한 그 교보타워...!
이전에 글또 코어 커피챗 모임에서도 신논현 근처에서 본 적이 있는지라 한번 슥 지나갔었는데 그게 이 건물일 줄은 몰랐다 어어엄청 컸다
당근 사옥 도착...
거의 시골쥐마냥 사진 왕창 찍고 싶었는데 쫄려서 많이는 못 찍고 당근 로고만 찍었다
중앙에 있던 당근 마스코트인지 ㅜ 인형 무지하게 귀여웠음
발표는 당근마켓 데이터 엔지니어 한 분과 데이터 브릭스에서 나온 이사님 한 분 이렇게 발표를 진행하시고 이후에는 네트워킹 모임을 진행했다
발표 이전에 프로도님께서 제일 멀리서 온 사람 책 드린다고 하길래 번쩍 손들어서 부산에서 왔다고 했는데 어쩌다 여기까지 왔냐 물으시는데 진심 당황해서 어쩌다 미팅 때문에 올라왔다고 함 아 그거 아니고 한데모 여러분들과 네트워킹 하고 싶어서 왔다고 했어야 했는데 후회... (E인데 왜 그랬을까 ㅜ)
주제는 다음과 같았다!
당근마켓에서 MAU 1800만의 사용자 이벤트를 처리하는 방법
오픈 데이터 레이크 하우스를 위한 Delta Lake
당근마켓 발표는 MAU 1800만에서 발표 시작하셨을 때 1900만으로 바꾼 채로 발표하셨다 ㅋㅋㅋ 진짜 엄청난 유저 수다...... 생에 겪어볼 숫자인가 싶다
당근마켓에서 MAU 1800만의 사용자 이벤트를 처리하는 방법
발표 내용은 사용자 이벤트 파이프라인에서 일어나는 이슈들을 개선한 사례에 관한 것이었다
한 시간마다 준 실시간으로 배치 파이프라인을 구성했었는데 데이터의 양이 늘어나면서 적재되는 시간이 배치 주기보다 늘어나는 이슈가 있었던 것이다
워커를 늘리거나 비용을 많이 써도 한계가 있다고 판단했기 때문에 아키텍처를 개선해야겠다고 판단을 하셨다고 한다
확장성과 실시간성, 운영 비용을 고려해서 설계를 했다고 함
기존에는 키네시스를 이용해서 EMR에서 스파크 배치로 빅쿼리에 데이터를 적재하는 방식이었는데 이걸 아예 GCP 환경으로 바꿔서 MSK로 데이터를 태우고 gcp pub/sub 으로 전달한다 이후 data flow 를 이용해서 데이터를 정제하고 pub/sub을 이용해서 또 정제하고 이런 식으로 운영 방식을 바꿨다고 한다 gcp에서 하고자 하는 이 펍섭과 데이터 플로우는 관리형 스트리밍 배치 서비스인 것이다
해당 아키텍처를 설계하고 운영하면서 이루어지는 이슈들도 공유해 주시고 여러모로 내 업무에 적용도 가능하겠다 싶은 인사이트들을 많이 얻었음
오픈 데이터 레이크 하우스를 위한 Delta Lake
두 번째 발표는 데이터 브릭스의 고영경 이사님이 발표를 하셨다
이 발표를 보기 전에도 이미 데이터 브릭스 도입에 대해 고려를 하고 있었던 지라 브릭스 컨퍼런스도 신청을 해 두었는데 그 세션에서 발표를 하신다고 함 우리한테 미리 보여 드리는 거라고 ㅋㅋㅋㅋ 이런 꿀정보가
사실 하이브 구조로도 일을 해 보지 않았고 하둡도 안 써 봐서... ㅜ 곧바로 데이터 레이크 구조가 나와 버리니까 이해하기에는 좀 힘들긴 했다 아직 많이 모자람 ..
델타 레이크라고 함은 간단하게 말하면 파케이 기반의 오픈 포맷이다. 즉 데이터 레이크를 위한 오픈 테이블 포맷인 것이다.
데이터 레이크에 스토리지 프레임워크가 왜 필요할까?
아파치 후디, 아이스버스, 델타레이크와 같은 테이블 포맷에 대한 이야기가 많이 나왔고 실제로도 도입을 많이 하는 추세인데 이게 대체 뭐냐? 라고 한다면...
내가 이해한 바로는 아마 S3 같은 데이터 레이크에 모든 데이터를 막 적재를 시키고, 파케이 형태로 테이블 데이터들을 파티션을 나누어서 적재를 시키는데 이게 관리가 잘 안 되니까 저런 니즈가 생긴 게 아닐까 싶다
필기는 아주 열심히 했는데 ㅋㅋ 이 발표를 듣고 나니 23일에 있을 브릭스 컨퍼런스가 더 기대됐다
시야가 넓어진다는 건 뭔가 희망이 생기는 것과 같은 느낌인 듯하다
이후 발표가 끝나고 네트워킹 시간을 가졌는데, 주변 분들께서 먼저 부산에서 오셨냐고 말 걸어주시고 업무적인 이야기를 했었는데 하필 또 모여서 같이 대화 나눈 분들이 모두 it 회사가 아니라 다른 도메인에 있는 데이터 엔지니어 분이셨다
딱 데이터엔지니어 -> 시각화 (BI) 까지 담당하시는 분들이었고 업무 과정이 나와 비슷해서 동질감을 느낀 채 대화를 많이 했다
나처럼 혼자 일을 하시는 분들도 계셨고 데이터 팀이 존재해서 협업을 잘하고 계신 분도 있었는데 나는 지금 데이터 인프라를 구축하기 위해 조사를 많이 해야 하는 입장이니 어떤 파이프라인을 사용하고 있는지, 혼자 운영하기도 괜찮은지, 비용 관리는 어떻게 하는지에 대한 꿀팁들을 많이 얻어 갔다
대외활동을 많이 해야 하는 이유 중 하나..... 규모가 적은 조직에서 일을 하다 보면 고독한 일이 참 많은데 이런 기회를 통해서 업무적인 회의감이나 궁금함을 풀어나갈 수 있다는 게 정말 좋은 일이다 더 열심히 공부하고 실력을 늘려야겠다는 마음 가짐을 또 한 번 잡게 된 날이었다
[글또xUdemy] AWS Certified Solutions Architect Associate 시험합격! 강의 후기 에 이어 두 번째로 선택한 강의는 Spark 관련 강의였는데요. 데이터 엔지니어링과 데이터 인프라 구축 니즈가 올라가면서 데이터를 다루는 조직들에게는 Spark가 거의 필수 요소가 되었습니다. 지금 제가 속한 조직은 Spark를 사용하지 않고 그대로 데이터베이스 서버를 이용해서 리소스를 사용하고 있는데요, 데이터 파이프라인을 새롭게 구축하면서 Spark 에 관한 내부 구조와 관련 문법들 이 엔진이 대용량 처리에 왜 유리한지에 대해 하나하나 짚어보고자 해당 강의를 선택하게 되었습니다. 아직 다 보진 않았지만 내부 구조에 대해서 그렇게 자세하게 알려주진 않고 실무에 어떻게 쓰이는지 실습이 주로 이루어진 강의입니다.
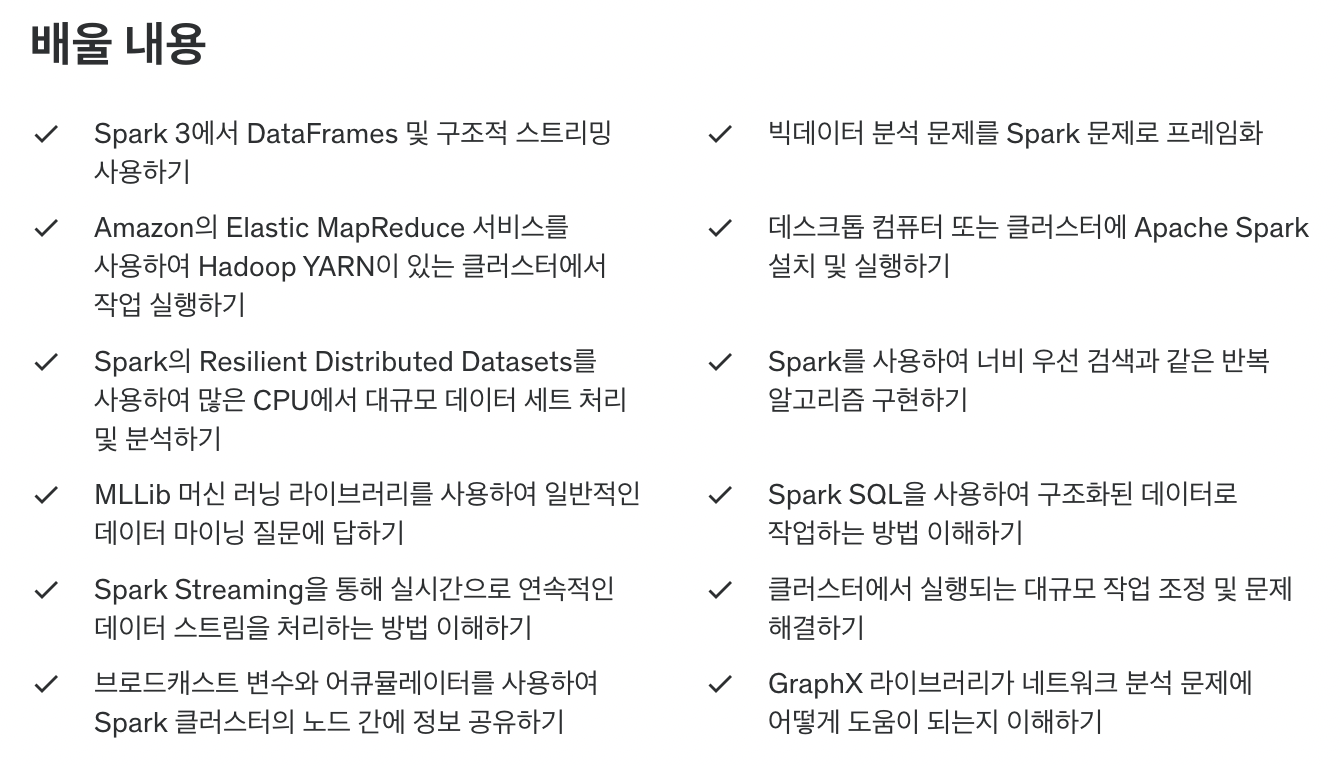
이 강의에서 다루는 내용은 다음과 같습니다. 저는 데이터 마이닝까지는 필요가 없어서 실시간으로 처리되는 데이터 스트림과 Spark SQL, 클러스터와 노드 위에서 이루어지는 개념과 같은 것들에 중점을 맞추어서 강의를 들었습니다.
강의 목차는 다음과 같습니다.
Spark의 데이터 구조인 RDD, DataFrames, DataSets에 대해서 개념을 정립하고 해당 구조에 대해 이해할 수 있게 실습을 진행합니다. 추가로 Spark ML도 다루고 있으니 머신러닝 분석하시려는 분들에게도 도움이 될 것 같네요
이런 분에겐 추천해요
Spark가 완전 처음이다
너무 자세하게는 말고 간단하게 큰 그림으로 훑어 보고 싶다
책보다는 강의 보면서 코드를 따라치면서 배우는 게 성향에 맞다
당장 실무에서 어떻게 사용할 수 있는지 알고 싶다
이런 분한테는 비추...
Spark에 대해서 어느 정도 알고 사용 중인데 레벨업을 하고 싶다
Spark를 활용한 응용 작업에 대해서 자세하게 알고 싶다
클라우드 환경에서 Spark 엔진이 내장된 서비스를 이미 사용 중이다
파이썬을 배운 적이 없다
확실히 실습 위주가 많은 강의입니다. 생각보다 이론에 대한 주제는 짚어주지 않고 이미 Spark를 도입해서 사용 중이신 분들에게는 맞지 않을 것 같다는 생각이 들더라고요. 저는 실무에서 Spark를 사용해 본 적이 없기에 어느 정도 개념 잡으면서 코드 따라 쳐보면서 실습하니까 대충 플로우가 어떻게 흘러가는지는 감이 잡히긴 했습니다. 심화 내용을 바라신다면 이 강의는 안 맞을 수 있어요!
강의 전반적인 내용
몇 년 전에 촬영한 내용이라 버전이 안 맞으면 어쩌지 싶었는데 버전에 대한 이슈들은 따로 체크를 해서 수정본을 업로드해 두셨습니다.
로컬 환경에서 Spark를 설치하여 실습을 하기 때문에 초반 설치 때문에 애를 많이 먹으실 수도 있습니다...... 강의 내용과는 좀 다를 수 있어서 저도 구글링을 하면서 설치를 하고 실습을 진행했습니다.
AWS EMR도 활용하는 강의가 나오는데, 이 부분은 따로 진행하지는 않았습니다.
PPT에 자료를 띄워 수업을 진행하시는데... 하늘색 화면에 글자만 계속 있어서 전체적으로 강의에 집중이 된다는 느낌은 안 들더라구요 ㅋㅋㅋ 그래도 차근차근 잘 따라가신다면 얻어가는 게 있으실 겁니다.
실습 내용에 따른 코드 흐름이 전부입니다. 전체적인 그림을 보기에는 최고인 것 같고 저같이 Spark가 처음인 사람들에게는 가볍게 개념 정리하기에는 좋은 것 같아요.
총평
장점과 단점은 위에서 언급을 했으니 간단한 총평만 진행하고 글을 마무리하겠습니다.
회사에서 이번에 데이터 파이프라인 개편 작업을 진행하면서 많은 자료조사들을 시작했었습니다. 데이터 엔지니어링에 필요한 로드맵을 정리해 둔 사이트가 있었는데요. 개인적으로 그 로드맵을 봤을 때는 내가 어떤 기술과 어떤 개념을 가져야 엔지니어로써의 자질을 쌓을 수 있을지 고민했다면 지금은 어떤 파이프라인과 로직, 기술들이 회사 프로세스에 맞을지 고민하는 과정을 거치면서 다뱡면의 상황을 고려해 적절한 기술을 사용하는 것에 대해서 판단을 할 수 있는 능력이 점차 쌓여가고 있는 것 같은 느낌을 받았습니다.
자료 조사를 하면서 항상 봤던 문구는 회사에 Spark를 사용하고 있지 않다면 도입을 하려는 시도는 해 보라는 말을 정말 많이 봤었는데요. 그걸 보면서 무작정 다른 회사는 다 spark 쓰고 있고 추후 이직을 위해서라도 spark를 나도 써 봐야 하는 거 아닐까? 라는 생각을 했지만 막상 도입을 위해 사유를 쓰려니 어떠한 사유로 spark를 써야 합니다 라고 설득 자료를 만들지를 못 하겠더라구요. 이유를 생각해 보니 저 자체가 Spark에 대한 개념 자체를 모르고 있기 때문에 무작정 도입만 고려하고 있었던 것이었습니다.
이번 강의를 들으면서 확실하게 얻어간 게 있는데요 ㅎㅎ 강의를 듣고 실습해 보면서 데이터 흐름에 대한 이해가 되었고, 현재 우리 회사의 프로세스에서 어떤 부분에 Spark 엔진을 사용하면 효율적일지에 대한 응용이 가능해졌다는 것에 대해 큰 도움이 되었다고 생각합니다.
강의에 대해서 궁금한 점이 있다면 언제든 댓글 남겨 주시면 답변 드리겠습니다. 감사합니다.
글또 9기를 시작하면서 유데미에서 강의를 지원받을 수 있는 기회를 받았습니다. 강의 수강 후 해당 강의에 대한 후기를 쓰는 것이 챌린지였는데요...! 평소에도 강의를 많이 결제해서 듣는 저에게는 선물이 아닐 수가 없습니다. 이전에도 알고리즘 강의를 유데미에서 결제해서 한참 듣고 있었거든요. 약 3 개월 동안의 두 편의 강의를 들으면서 느꼈던 후기를 풀어 보려고 합니다.
내가 이 강의를 선택한 이유
새로 입사한 곳에서 현재 온프렘 서비스들을 모두 AWS로 이관한다는 이야기를 들은 후 걱정 반 설렘 반이었습니다. AWS를 마음껏 만질 수 있다는 기대감과 설렘, 그리고 잘 모르는 상태에서 다루었을 때 다가올 풍파(?) 때문에 걱정이 많았는데요. 평소에도 SAA 자격증에 관심이 있기도 했고, [AWS의 모든 것] 이라는 오픈채팅방에서도 항상 자격증에 대한 자료들을 잘 올려주셔서 그걸 참고해서 자격증을 준비할까...... 하다가 유데미에서 지원해 주는 강의 목록에 SAA 전용 강의가 있길래 바로 신청을 해두었습니다! 올해 하반기 쯤에 SAA 자격증을 따 보려고 했는데 확실히 도움이 많이 될 것 같습니다.
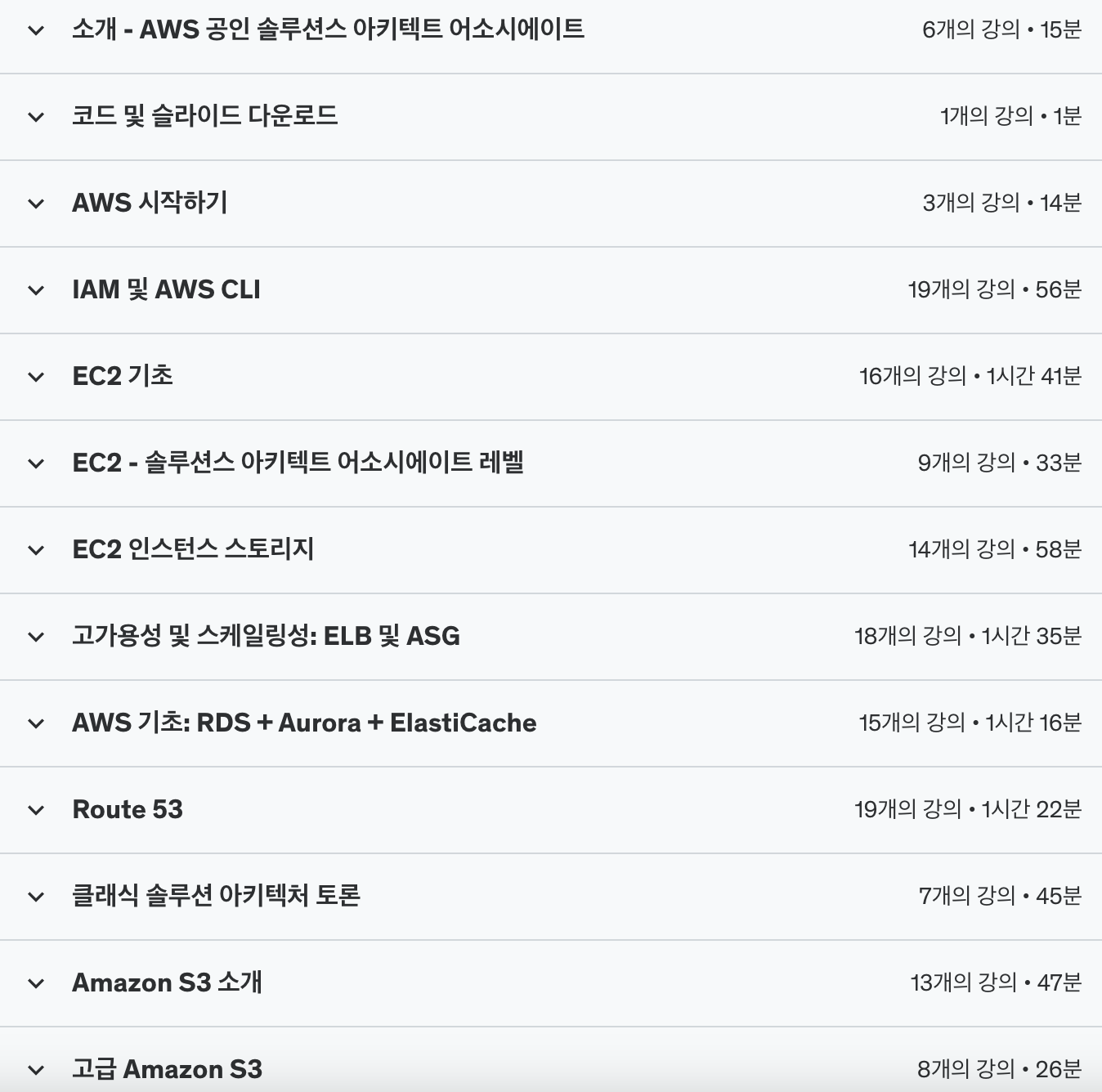
모니터링, 문제 해결 및 감사: AWS CloudWatch, X-Ray, CloudTrail
AWS 인테그레이션 및 메시징: SQS, SNS, Kinesis
AWS Serverless: AWS Lambda, DynamoDB, API Gateway, Cognito
AWS 보안 모범 사례: KMS, 암호화 SDK, SSM 파라미터 스토어, IAM 정책
VPC & 네트워킹 심층 분석
그 외 AWS 서비스 개요: CICD (CodeCommit, CodeBuild, CodePipeline, CodeDeploy), CloudFormation, ECS, Step Functions, SWF, EMR, Glue, OpsWorks, ElasticTranscoder, AWS Organizations, Workspaces, AppSync, Single Sign On (SSO)
시험 합격 팁
커리큘럼 안에는 구체적으로 저런 서비스들에 대해서 배우는데요. 확실히 지금 와서 다시 커리큘럼을 보니 전부 다 중요한 서비스들이네요...... 이 강의를 안 듣고 지금 실무 들어갔으면 어버버했을 것 같습니다.
수강 후기
느낀 점 및 기억에 남는 점
저는 회사 업무를 하면서도 온프렘 서버를 사용했었고, 사이드 프로젝트를 할 때도 해 봤자 EC2와 RDS 사용만 해 왔기 때문에 클라우드 서버라는 거대한 플랫폼이 어떻게 얼마나 사용이 되는지 어떤 식으로 구성을 해서 실제 현업에서 사용하는지 감이 잘 잡히지 않았었는데요. 흔히 들어왔던 로드밸런싱, IAM, 오토스케일링... 인프라 관리에 필요한 모든 것들과 네트워크 통신 등, CS 공부를 할 때 접했던 개념들이 기초 파트에서 나오니 확실히 뭐든 cs를 기반한 베이직 개념을 깔고 가야 하구나를 느꼈습니다. 이 년 전에 아마존 SA 직무로 면접을 봤던 적이 있었는데....... 엄청 털렸었거든요 ㅋㅋ 그때 생각이 많이 났습니다. 위에 적혀 있는 리스트만 대충 훑어 봐도 업계에서 안 쓰는 서비스들이 없지 않나요? 정말 모든 걸 다 사용하는 듯하여...... 새삼 공부하면서도 클라우드 개발자로서의 길도 생각해 보면 좋지 않을까 하는 생각도 들었었네요.
장점
SAA 자격증을 따기 위한 목표 때문에 강의를 선택했던 것도 있었지만, AWS의 전반적인 모든 서비스들을 빠르게 훑고 파악하는 것이 제 목표였기 때문에 더 좋은 선택이 아니었나 싶습니다. 기술 스택을 선택해야 하는 상황에서 어떤 서비스가 존재하지는지도 모르고 파이프라인을 짜는 건 말도 안 되니까요. 실제로 파이프라인 구성하는 데에 많은 도움이 되었습니다.
특히 S3, Athena, Redshift, Glue와 메시징 서비스 관련해서 궁금한 부분들이 많아 관련된 세션은 집중해서 들었던 기억이 있습니다.
커리큘럼 이름에서 실습 < 이 있는 주제들은 모두 설명과 더불어 실습을 직접 같이 해 보는 부분들이 있는데요 함께 따라해 보면서 환경 구성하는 방법과 실제로 내부에서 어떻게 동작하는지와 같은 테스트를 해 볼 수 있어 좋았습니다. 또한 VPC까지는 아직 강의를 듣지는 않았지만 AWS 서비스 연결하고 환경 세팅할 때 VPC가 정말..... 속을 많이 썩이더라구요? 네트워킹과 VPC 부분이 자세하게 나와 있어서 도움이 많이 되겠다 싶었습니다.
아쉬웠던 점
아무래도 시험에 나오는 부분을 중점으로 강의를 진행하다 보니 이론이 많았고 실습은 아마 프리티어 위주로만 진행을 한 것 같습니다. 예를 들어 저는 glue에 대해서 설정은 어떻게 하는지 실제로 구성은 어떻게 하는지...... 이런 걸 보고 싶었는데 거기까지는 세부적으로 설명해 주지 않더라구요. 이건 아마도 DEA-C01을 들어야 자세하게 나오는 부분이 아닌가 싶습니다. SAA 로서는 가볍게 훑고 넘어갔다는 점!
총평
심도있게 특정 서비스에 대해 알고 싶으신 분들은 SAA 강의가 안 맞을 수도 있습니다. 이건 정말 SAA 자격증 취득에 관한 강의 내용이기 때문에 전체적으로 훑으면서 흐름을 알고 가고 싶으신 분들께 추천해 드립니다. 저도 겸사겸사 SAA 준비도 함께 해 보자고 시작했는데 여러모로 지식이 많이 늘어나서 회사 업무상 AWS 관계자 분들과 미팅할 때도 큰 이슈 없이 잘 미팅하고 궁금한 것도 잘 캐치해서 물어봤던 것 같습니다. 왜, 아무것도 모르면 몰라서 질문할 게 없다는 말이 있잖아요. 다행히... ㅋㅋㅋ 공부를 하면서 모르는 부분들이 많이 생겨서 스스로 공부도 해 보고 물어보기도 하면서 조금이나마 성장할 수 있었습니다. 다시 한번 글또 운영진 분들과 강의 지원해 주신 유데미 관계자 분들께 감사 인사를 올리며... 올해 안으로 SAA 자격증 합격 후기로 돌아오겠습니다. 감사합니다.
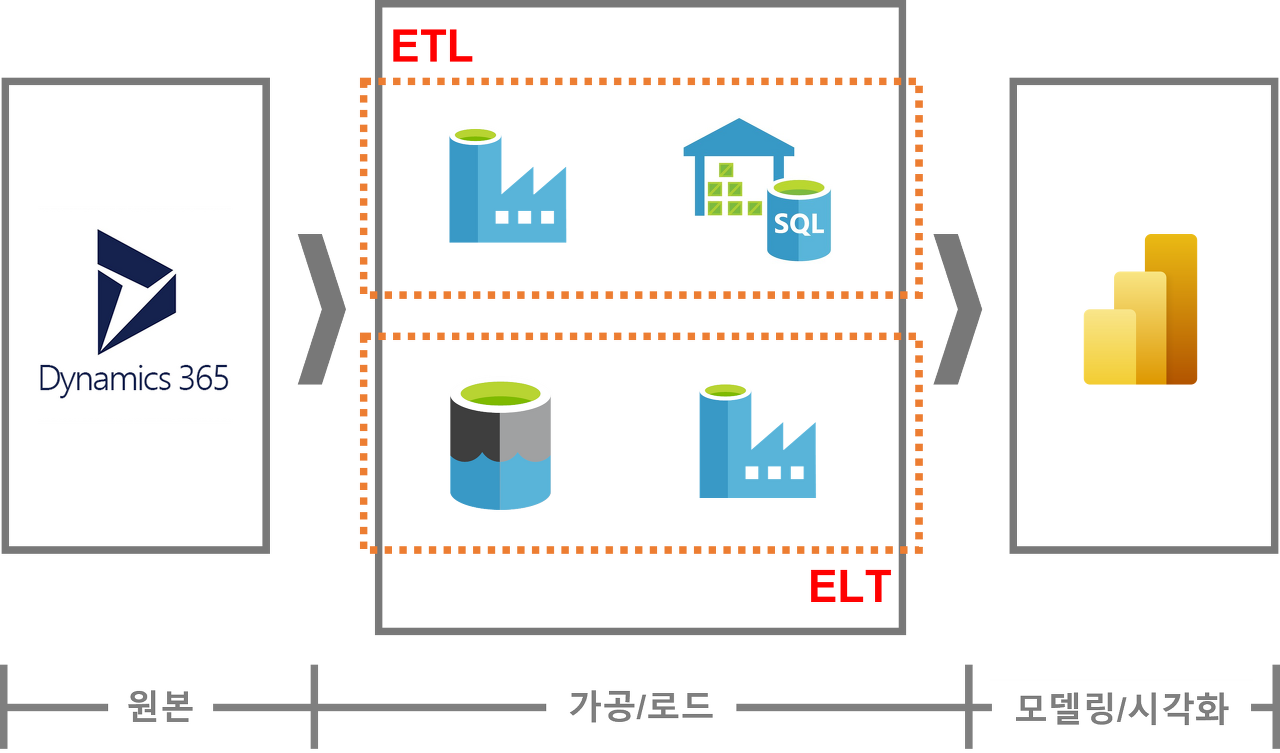
데이터 엔지지니어링에서 가장 중요한 파트를 뽑으라면 아마 ETL 단계가 아닐까 싶습니다. 모든 분석의 결과값에 사용되는 데이터들이 ETL 및 ELT 과정을 통해 DW 내에 적재되기 때문입니다.
최근 ETL에서 ELT로 거의 바뀌는 추세라고는 하지만 여전히 ETL을 사용하는 곳들이 많고 제가 다니고 있는 조직에서도 ETL 패턴을 유지하고 있기 때문에 효율성과 비용, 확장성을 고려해서 각자 회사 상황에 맞는 방식을 선택하는 것이 현명한 선택이라는 생각이 듭니다.
이번에 ETL 개편 자료 조사를 하면서 무작정 새로운 것들을 도입하는 것보단 뿌리부터 데이터 히스토리를 파악해서 가장 효율적인 방법을 찾아나가는 게 중요하다고 생각되어 제가 조사했던 ETL과 ELT의 차이점 및 어떤 상황에 해당 패턴을 사용하는 게 맞는 것인지를 작성해 보려고 합니다. 물론 모든 과정에 정답은 없습니다. 각자 상황에 맞게 프로세스를 꾸려나가는 것이 데이터 엔지니어의 숙명인 듯합니다.... ㅜㅜ
데이터를 원천에서 가져오는 추출(Extract), 추출한 데이터를 원하는 형태로 가공하는 변환(Transform), 변환 후 타겟 목적지까지 저장하는 적재(Load)의 흐름으로 진행됩니다.
불필요한 데이터를 추출하지 않고 원하는 데이터만 선택적으로 추출해서 저장소를 효율적으로 다룰 수 있다는 장점이 있습니다. 워낙에 보편화된 기술이고 관련한 기술자들이 많기 때문에 이런 형식을 다룰 수 있는 엔지니어분들이 많다는 것도 하나의 장점이 될 수 있겠습니다.
하지만 이 과정을 통해서 뭘 얻고자 하느냐? 결국 우리가 원하는 건 정제되고 시각화된 리포트들입니다.
예를 들어 매일 아침마다 매장별일매출을 확인한다던지, 판매량을 본다던지 일 배치로 매일매일 확인해야 하는 데이터들을 새벽마다 대용량의 데이터를 변환시켜 처리하려면 운영상의 난이도가 올라가고 관리가 빡세다는 단점이 있습니다.
또한 이미 해당 리포트에 맞게 테이블을 만들어 적재를 해 놓았으니 리포트를 사용하는 팀에서 다른 형식으로 데이터를 뽑아달라는 요청이 왔을 때 그 형태에 맞게 또 다른 테이블을 생성해서 적재를 진행해야 한다는 게 가장 크리티컬한 단점이 아닐까 싶습니다.
저희 부서 같은 경우는 아직 ETL 형식을 사용하고 있어 마스터 테이블이라는 개념을 빌려 모든 경우의 수를 다 조합할 수 있는 원천 데이터들을 조인해서 모든 데이터가 담긴 ODS 테이블을 만들어 두었습니다. 뭐 이런 식으로도 방법을 만들 수는 있겠지만 컬럼이 200 개정도가 넘어가는 불상사가... ^^; 그 테이블을 바라보고 결국 다른 팩트 테이블을 설계해야 하는데 유지보수 측면으로도 영 이게 맞는 건지 썩 마음에 들진 않습니다. 하지만 더 효율적이고 괜찮은 방법이 생각나지 않아요 ㅠㅠㅠ 클라우드 dw를 도입할 수 있는 환경도 아니라.. 도입한다고 해도 비용 관리를 혼자 다 해야 한다는 부담감이.. 어흑
ETL에 사용되는 툴은 다음과 같습니다.
인포매티카 PowerCenter
Pentaho ETL
FiveTran, Stitch Data
Airflow
다른 클라우드 서비스 (AWS Glue, etc ...)
파이브트란이나 스티치 같은 경우에는 CDC도 지원을 해 주고 SaaS형 솔루션이기 때문에 꽤나 비용이 비싼 것으로 보였습니다. ETL한 행수 별로 월 비용처리를 한다거나 그랬던 것 같고 인포매티카는 사용해보진 않았지만 한국 지사 철수로 아마 지금 당장 도입은 안 되는 걸로 알고 있습니다 ㅎ 펜타호도 마찬가지로 네이버 클라우드 기준 제일 싼 게 월 250 이더라구요. 물론 무료 버전인 CE 버전도 있습니다만 간단한 처리를 하기엔 좋지만 오류가 났을 때의 단점이 좀 있어서 상황에 맞는 스케줄러나 프레임워크를 도입하는 것이 좋겠습니다.
ETL과 다르게 변환의 순서가 다릅니다. 데이터를 추출한 다음 바로 적재를 하고, 후에 변환을 하는 시스템입니다. 거의 클라우드 DW가 등장을 하면서부터 ELT의 방식이 점점 늘어나는 추세가 된 것 같습니다.
AWS로 예를 들자면 원천 데이터를 S3에 적재한 후 glue로 S3를 읽어 들여 RDB의 테이블 형태로 만들어 (glue 데이터 카탈로그의 기능) Athena 혹은 RedShift에 Load 해서 아테나와 레드시프트 안에서 Transform을 하는 방식의 시스템인 것입니다.
이러한 방식의 장점은 데이터 변환이 DW 안에서 이루어지기 때문에 변환되어서 적재가 되는 과정에 오류가 생겨서 적재가 되지 않거나 네트워크가 끊겨서 멈췄다거나 하는 그런 걱정이 하나도 없을 수가 있고, 원본 데이터를 모두 가지고 있기 때문에 필요할 때마다 빠르게 바로 가져다 원하는 형태의 분석 데이터를 만들 수 있습니다.
클라우드 DW들을 사용해 본 적이 없어서 잘 모르겠는데, 로드된 데이터 자체가 일단 원천 데이터인데 혹시 그 원천 데이터에서 데이터 오류가 발생하였다면? 그때의 오류를 어떻게 해결하고 데이터 품질 관리는 어떻게 진행해야 할지는 잘 감이 안 잡히긴 하네요...... 원천에서부터 오류가 난다면 그건 데이터 엔지니어링에서 해결할 수 없는 부분이긴 하지만 그 부분은 제외하고 분석에 활용을 하는 건지...... 는 갑자기 궁금해진 부분이네요.
그렇다면 언제 ELT를 사용해야 하는지?
대용량, 다양한 데이터를 보유했을 때 -> ELT는 정형 데이터와 비정형 데이터를 모두 아우를 수 있습니다.
빠르게 처리해야 할 때 -> 스트리밍 데이터를 필요로 할 때 ELT로 처리하는 것이 효율적일 수 있습니다.
어떻게 분석해야 할지는 모르겠는데 일단 데이터 저장은 필요해! -> 저장 스토리지 비용이 쿼리 한번 돌리는 것보다 싸기 때문에 오히려 먼저 적재해놓고 나중에 분석하는 게 더 효율적이라고 판단할 수도 있겠네요..
ELT에서 살펴봐야 할 프레임워크 및 클라우드 DW, 옵션들은 다음과 같습니다.
AWS RedShift
AWS Athena
Snowflake
GCP BigQuery
Apache Hive
Apache Presto
Apache Iceberg
Apache Spark
레드시프트는 다들 비용이 부담이 돼서 거의 아테나로 넘어가는 걸 권장한다고 어디서 들은 것 같은데...... 둘 다 사용을 해보질 않았으니 저는 첨언할 게 없네요 ㅠ 개인적으로 데이터 엔지니어링 쪽은 GCP가 정말 효율적으로 잘 사용할 수 있을 것 같은데 저희 회사는 또 AWS 서버 기반이라 빅쿼리 도입한다고 하면 설득도 전에 이미 문전박대가 되지 않을까 싶네요..
클라우드 DW가 우리 조직에게 필요한가를 생각해 봤을 때 저는 이 정도의 질문을 스스로에게 남겼습니다
현재 조직의 리소스가 어떻게 되는가?
RDS Oracle 계약으로 사용 중 -> DW도 오라클에 단독 dw 서버 만들어 적재 중
ETL에 드는 비용은 없음. 펜타호 무료 버전 사용 중. 하지만 DB의 과부하, 트래픽 비용, 원인을 찾을 수 없는 디비락 ㅜ, 시간소요, 네트워크 전송 실패 문제로 어떻게든 툴을 바꾸거나 데이터 파이프라인 개선이 필요한 상황
이미 나가고 있을 돈은 다 나가고 있다. 도입을 하면 추가 비용만 발생할 텐데 여기서 비용으로 승부를 볼 수 있을까?
BI 툴도 라이센스 계약으로 사용 중이라 ETL과 DW단만 지지고 볶으면 된다.
=> 원천데이터를 ODS에 적재하는 부분을 감소시키자. 현재 RDS의 용량을 원천데이터에서 ODS로 그대로 복사해서 사용하고 있기 때문에 이 과정을 S3에 저장시키고 (비용 감소) Athena로 분석 테이블들을 생성시키면 일도 간편해지고 관리에도 용이할 것으로 보임
정도로 결론을 내렸지만 어떻게 진정성 있게 설득을 할지가 지금 현재 저의 고민인 것 같습니다. 그래도 글을 쓰면서도 조금 정리가 되긴 되어서 스스로에게도 도움이 되긴 했네요.
관련 자료를 찾아 보다 사례를 통한 아키텍처가 있어 참고해 보면 좋을 것 같아 첨부합니다.
1) 보고서 내용이 바뀌거나 추가되면 데이터를 그에 맞춰 다시 가공하고 다시 로드해야 함. 가공 단계부터 다시 시작해야 됨
2) 실제 보고서를 만들 때, 가공해서 로드한 모든 데이터를 사용하지 않게 될 수도 있음. 낭비된 비용 발생
3) 가공 전 데이터에 접근하여 다른 가공을 해봐야 하는 상황이 생길 수 있음. 이 경우, 가공 전 데이터를 원본에서부터 다시 끌고 와야 함. ==> 여기서 그 원본 데이터가 어디에 있는지부터 또 찾아야 함. 그리고 ETL 작업을 다시 하고 원천 데이터 가져오는 ETL, 가져와서 가공하는 ETL을 또 만들어야 됨
ELT 사용 시)
1. 시각화 보고서를 개발하기 위한 데이터 모델 설계
2. 고객 및 매출 관련 데이터를 가져와 우선 전부 로드
3. 1에서 설계한 모델에 맞춰 로드된 데이터 중 필요한 데이터만 가져와 가공
4. 가공한 데이터로 실제 모델링 및 시각화 보고서 개발 진행
** 고려사항
1) 보고서 내용이 바뀌거나 추가되면 로드된 데이터 내에서부터 가공하면 됨. 로드 이전에 가공하는 게 아니라 로드 후 가공이라 비용과 시간이 줄어듦.
2) 실제 보고서를 만들 때, 로드되어 있는 데이터 중 필요한 데이터만 가져와 모델링 및 시각화를 진행함. 낭비되는 비용이 발생하지 않음.
3) 가공 전 데이터에 접근하여 다른 가공을 해봐야 하는 상황이 생길 수 있음. 이 경우 이미 로드되어 있는 데이터만 확인하면 됨.
그렇다면 내가 지금 ODS에 원천에서 들고 올 수 있는 데이터 다 들고 와서 200개 컬럼이 들어있는 테이블은 과연 불필요한 낭비 비용인 ETL인 것인가 우선 고객 매출 관련 데이터를 전부 로드한 ELT인 것인가...... 갑자기 또 의문점이 들었네요. RDS가 비싸니까 낭비라고 보면 되는 걸까요? 스토리지 비용으로? 그렇다면 그 스토리지를 없애고 S3로 간다면 비용이 절약되는 건지? 또 고민이 시작되었습니다... 클라우드 DW만 아니다 뿐이지 일단 모두 다 로드해서 적재해놓긴 했는데 실시간 쿼리 분석이 안 된다는 점에서 패착이 있긴 하지만 또 실시간 분석 리포트를 진행하고 있는 건 아니라... ELT로 가게 된다면 실시간 리포트로 확인할 수 있다는 점에서 확장성이 있기는 하네요.
어찌됐든 상황에 따른 최대한의 좋은 방안은 설계한 사람이 생각하기 나름인 것 같습니다.
확실히 현업 관련 사례를 보면서 차이점을 보니 어떤 상황에서 비용을 더 아낄 수 있고 운영하기에도 용이한지 한눈에 파악이 되는 것 같습니다. 같은 고민을 하시는 분들이 있다면 조금이나마 도움이 되셨으면 좋겠습니다.
안녕하세요 :D 활동하고 있는 글또에서 코드 트리 이용권을 받아 8 주 동안 체험할 수 있는 기회를 얻게 되었습니다!
관련 운영진 분들께 우선 감사의 말씀을 드리고.......
코드 트리를 이용해 본 며칠 솔직 후기를 남겨 보겠습니다
이번 글은 이런 분이 읽으시면 좋아요
취업 준비할 때 코딩 테스트를 준비해 본 적이 없다
어느 정도 코딩도 할 줄 알고 cs 지식도 있지만 코딩 테스트 문제 자체를 풀기에 진입 장벽이 있다
백준이나 프로그래머스를 풀려고 봤는데 레벨 1도 어떻게 풀어야 할지 감이 안 잡힌다
저는 항상 이직을 준비할 때면 코딩 테스트를 응시하는 기업은 채용 공고를 보자마자 시선을 돌리거나 다른 기업을 찾곤 했는데요...... 전공자임에도 불구하고 ^^; 입사한 회사들마다 코딩 테스트를 요하지 않았기 때문에 따로 준비를 하지 않아서 코테는 거의 기피 대상이었습니다 ㅠ
하지만 2 년차가 지나가고...... 코테를 미루고 미루다 보면 더 큰 도전을 할 수 없을 것 같다는 생각에 코테와 알고리즘을 준비해야겠다며 결심을 했지만 코딩 테스트 문제를 봐도 어떤 알고리즘을 이용해서 문제를 풀어야 할지 어떻게 접근을 해야 할지 모르겠었고 개발 실력과는 다르게 넘어야 할 산이 많은 것처럼 느껴지더라구요 그러다 또 포기하고 시간은 지나고 3 년차가 되어 버렸습니다 😅
코딩 테스트는 항상 제 마음의 짐 같은 거였고...... 이제는 정말 준비를 해야 하지 않나 이런 고민을 하던 차에!! 코드 트리에서 좋은 기회를 얻었고 거의 문제 푸는 방식에 대해 감도 잡지 못 하는 저는 초기 레벨부터 시작해 보고자 하였습니다.
실력 진단
처음 코드 트리에 들어가게 되면 실력 진단을 할 수 있습니다. 현재 내가 어떤 상황인지 체크하는 문항들이고 응답 내용을 바탕으로 몇 가지 플랜을 보여 주는데요, 저는 코딩 테스트 준비를 제대로 해 보지 않았기 때문에 우선 진단 평가부터 시작하였습니다.
전 맨 처음 문제를 풀었을 때도 (한 달 전...) 오랜만에 문법에 따라 문제를 풀려니 기억이 가물가물하더라구요 ㅋㅋ 코드 안 친지 너무 오래 돼서...... ㅠ 요즘 SQL이랑 인프라만 다루고 있다 보니 역시 인간은 망각의 동물이라고 안 하니까 좀 더디더라구요
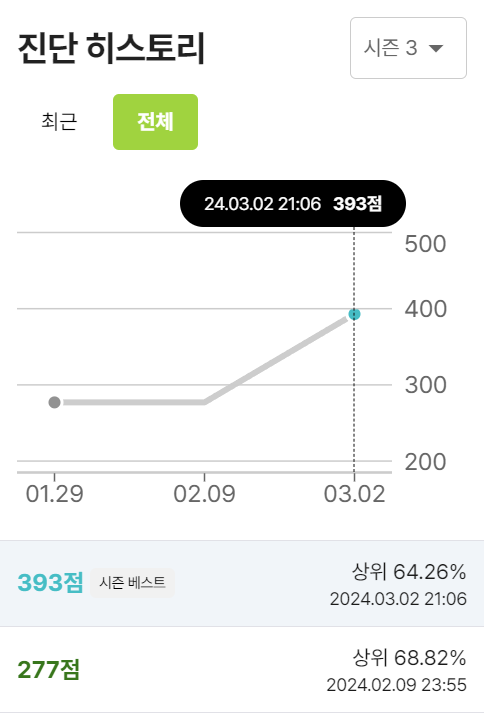
처음 진단 결과를 받았을 때 이렇게 진단을 해줍니다! 어떤 부분이 부족한지, 얼마나 더 하면 실력이 늘 수 있는지에 대한 예측까지 같이 해 주니 더욱 더 의지가 올라갔다고나 해야 할까요 ㅋㅋ
이 사진은 글 쓰기 전에 재진단을 해 본 점수이고 한 달전에 진단 받았던 히스토리까지 볼 수 있어서 상승 곡선을 볼 수 있답니다
여전히 낮은 점수지만 (당연함 ㅜ 꾸준히 하지 못한 저의 잘못...) 그래도 문제를 보면서 아 이건 이 문법을 써야 풀리는 거구나 이건 이 알고리즘을 쓰면서 푸는 거구나! 하는 문제 접근법에 대해서 감을 좀 깨우친 한달이었습니다
테스트 문제에서 수열 문제가 나오길래 그냥 바로 패스했는데 리스트를 사용하는 문제였습니다...... 이렇게 또 하나 배워가는 거죠 ㅎ 대학생 때 열심히 해 둘걸 후회하는 중이지만 ㅠ 지금이라도 열심히 하고 있음에 다행이라고 생각합니다.
커리큘럼
문제를 풀기 전 나에게 맞는 커리큘럼이 나오는데요, 저는 아예 처음부터 커리큘럼 초반인 프로그래밍 기초 - Novice Low 부터 시작하였습니다.
상대적으로 쉬운 문제들이라 37 문제까지 한 5 일 정도 걸린 것 같아요 퇴근하고 조금 조금씩 풀어보다가 최근엔 업무 때문에 바빠서(핑계) 자주 못 했지만 꾸준히 하루에 한 문제씩이라도 계속 풀면 정말 한 달 전과는 다른 나를 볼 수 있을 것 같다는 생각이 들었습니다 ㅎㅎ
다른 코테 사이트와는 다른 점이 코드 트리에서는 문제 유형을 보면서 문제를 풀 수 있게 한다는 점이 초반 코테 스퍼트 잡을 때 길잡이가 엄청 잘 된다 라고 볼 수 있겠습니다 스텝바이스텝으로 차근차근히 유형에 대해 밟으면서 간다는 그 부분에서 저는 엄청 덕을 많이 봤거든요 !
저의 목표는 남은 한 달동안은 정말 빼먹지 않고 하루에 한 문제씩이라도 Low를 다 끝내고 Novice High 까지는 끝내는 것을 목표로 잡았습니다 ㅠ 귀한 기회를 잘 뽑아 먹어서 한 달 뒤 후기도 남겨 보겠습니다.
다음으로 프로그래밍 기초를 완료한다면 프로그래밍 연습으로 넘어가게 되는데요. 각 커리큘럼에 대한 설명도 친절하고 자세하게 해 놓아서 너무 문제를 풀고 싶게.... (?) 화면 구성을 했다는 점에 또 감탄을 했습니다 ㅋㅋㅋ
코테린이인 나도 코드 트리를 거치면 코테 마스터?!
글만 봐도 너무 문제를 풀어보고 싶게 생기지 않았나요 ㅋㅋㅋㅋㅋ 하루 종일 문제를 붙잡고서라도 얼른 끝내고 싶은 마음이 듭니다...... 제 깃헙도 잔디로 채우고요 ㅠㅠ
아, 말이 나온 김에 또 덧붙여서 코드 트리의 장점은 깃허브와 연동이 된다는 것인데요. 굳이 크롬 확장 프로그램에서 뭘 설치하지 않아도 로그인 시 깃헙 연동만 해 놓으면 문제를 푸는 즉시 본인의 레포지토리에 커밋이 됩니다. 잔디 관리도 되면서 또 눈에 보이니까 성취감이 들면서 꾸준히 해야겠다는 생각이 자연스럽게 들었어요 ㅎ
아이고 휑하다 ㅎ
오른쪽 2월에 그래도 꽤나 쌓인 잔디들이 코드트리를 하면서 쌓은 잔디들인데요! 이렇게라도 깃허브 관리도 함께 할 수 있고.... 물론 다른 사이트들도 다 되긴 하지만 연동성이 정말 좋더라구요
단점: 매일매일 쌓이다 보면 하루라도 안 하면 안될 것 같다는 강박이 생길 수 있다
하지만 그건 생각하지 말고 매일 매일 안 했더라도 오늘 했으면 오늘 한 거에 대한 자신에게 칭찬을 해주길!!!! 매일 하다가 하루 안 했다고 아 난 틀렸어 하고 포기하기 말기!!!! << 제일 바보 같은 짓이다.
회고
지난 한 달 간의 후기를 작성하면서 반성 많이 했습니다. 일주일 정도는 열심히 했는데 한 번 놓치니까 또 안 하게 되더라구요 사람이.. ^^; 이번 회고를 쓰면서 코드 트리 재진단도 해 보고 그래도 Novice Low에서 풀었던 문제 유형 중에서는 하나도 안 틀리고 다 통과를 했고 공부 안 한 부분만 부족하다 나오니 확실히 효과는 있다 싶었습니다. 제가 너무 쉬운 걸 풀어서 그런 걸 수도 있지만 ㅎㅎ 확실히 코드트리 통해서 유형별 스텝을 밟아간 후에 다시 문제를 보니까 문제가 단순히 수능 지문처럼 안 보이고 풀 수 있는 문제로 보였습니다 ㅋㅋㅋ 어떻게 풀어야 할지 감이 잡히고 일단 나만의 코드 템플릿이 조금 정해지는 느낌? 그런 게 들면서 재미가 붙기 시작했어요. 개인적으로 코드 트리 이용일이 끝나도 결제해서 준비를 해야겠다 싶은 생각이 드네요. 남은 한 달 간 꾸준히 진행해서 달라진 모습으로 2 번째 회고 준비해 보겠습니다. 글 봐주셔서 감사합니다 ㅎㅎ 궁금한 점 있으면 댓글 남겨주세요
대용량 데이터를 전송할 때 사용하는 여러가지 방법이 있는데 그 중 하나가 Message Queue를 이용한 방법이 있습니다.
요즘 카프카가 대세다, 대용량 데이터를 처리하는 방법 등등 이런 헤드라인으로 시선을 사로잡는 광고들이 많이 보였습니다. (이미 현업에서도 많이 사용 중이지만...) 저도 데이터를 만지는 사람으로써 이런 기술들에 대한 니즈가 있긴 하지만 당장에 내 상황에 필요한 기술인지 아닌지에 대해 판단도 못 하겠고, 왜 MQ나, Kafka 같은 것들을 도입하여 사용하는지 어떤 상황에 맞게 쓰는 게 맞는지 근본적인 의문을 풀어보고자 이 글을 작성하게 되었습니다. 이 글은 제가 공부하면서 정리하고 적어 보는 거니 완전히 믿으시면 안 됩니다....! (밑밥깔기)
Message Queue란 무엇인가?
참고글 https://earlybird.kr/1489 메세지 큐의 정의에 대해 찾아 보다가 이런 블로그를 찾게 되었는데 정말 가려운 곳을 긁어주는 글이었습니다. 십 년 전 글이지만 저와 똑같은 의문점을 가지고 글을 작성하셨더라구요..! 저도 학교 수업이나 정처기 공부했을 때 IPC(Inter-process communication)를 들어보았었는데 이때 OS에서 관리되는 이벤트들이 메세지큐를 통해서 관리된다고 알고 있었어서 처음에는 그런 느낌의 메세지큐를 말하는 건가? 싶었는데 개념은 비슷하지만 그걸 뜻한 건 아니었었네요.
여기서 말하는 Queue도 우리가 알고 있는 그 큐가 맞습니다. FIFO 패턴을 따라서 데이터가 큐에 들어가게 되면, 먼저 들어간 순서대로 제거가 됩니다.
Message Queue는 분산 시스템에서 데이터를 비동기적으로 전송하고 처리하는 데에 사용되는 시스템입니다. 아키텍처는 다음과 같습니다.
1. Producer(생성자): 데이터나 이벤트를 생성하고, 메세지 큐로 보내는 역할 2. Comsumer(소비자): 메세지 큐에서 메세지를 가져와서 처리하는 역할 3. Message Broker: 3-1. Queue가 정의되어 있는 third-party software 3-2. 다양한 유형의 메세지를 다른 Queue로 라우팅하기 위한 규칙도 제공한다 3-3. Producer와 Consumer 간의 중간 역할
--> 여기서 헷갈리면 안 되는 게, 메세지 큐는 데이터 구조로서 메세지를 보관하는 방법인 것이고 메세지 브로커는 큐를 관리하는 별도의 구성요소라고 이해하면 됩니다.
왜 Message Queue를 사용할까?
대용량 데이터 같은 경우 일반적인 서버단에서 그냥 처리를 하게 되면 1. 오래 걸리고 (속도) 2. 중간에 과부하가 걸려 터질 수도 있고 (트래픽 문제) 3. 안정적이지 않아 데이터가 제대로 넘어가지 않을 수 있고. (신뢰성) 4. 또한 유지보수도 힘들 수 있습니다. (확장성)
메세지큐의 통신 과정을 보게 되면 생성자가 소비자에게 직접 데이터를 받으라고 요청하는 것이 아니라, 생성자가 중간 큐 단에 xml이나 json 형식으로 데이터를 전달하게 되면 소비자는 큐로부터 요청 데이터를 받아서 처리를 하게 됩니다. 그래서 만약 소비자가 큐에서 데이터를 받을 수 없는 상황이라면 해당 데이터는 큐에 계속 남아있게 되는 것이죠. 그렇게 해서 소비자 서버가 다시 안정화가 되었을 때 큐에 요청을 해서 처리를 할 수 있게 됩니다.
여기서 조금 더 자세하게 이야기하자면 소비자가 죽어버리는 상황에서 볼 수 있는 것이 DLQ 인데요. Dead-Letter Queue는 하나 이상의 Source Queue가 성공적으로 컨슘되지 못한 메시지들을 재전송하기 위해 사용하는 별도의 큐입니다. DLQ에 쌓인 메시지들을 보면 왜 이 메시지들이 소비자에 의해 처리되지 못했는지를 알 수 있어서 서버가 죽더라도 DLQ를 확인해 보면 이게 잘 들어갔는지 에러가 났는지 확인해 볼 수 있어요.
각자 메세지 큐를 통해 구현하고자 하는 상황들이 다르겠지만, 공통적인 키워드는 1. 비동기 통신을 원할 때 2. 분산 환경에서 데이터를 안전하게 전달하고 싶을 때 3. 보낸 사람과 받는 사람이 분리되어 있을 때 가 아닐까 싶네요.....
실제 Message Queue의 사용 사례는 어떤 것이 있을까? - 주문, 재고 업데이트, 배송 등의 서비스 흐름을 관리하고 싶을 때 - SNS 알림 관리 - 실시간 채팅 - 게임에서 유저들끼리 매칭을 진행할 때 - 티켓팅할 때 대기인원수 표시하는 것도 아마도 메세지 큐....?!를 이용한 것 같네요
Message Queue의 종류
MQ의 종류로는 여러가지가 있는데 ActiveMQ, RabbitMQ, Kafka, AWS MQ, AWS SQS 등이 있습니다. 위에서도 말했다시피 각각의 시스템마다 사용할 때 더 효율적인 상황이 존재합니다. 각각의 특성들만 간단히 정리해 보고 다음 글에서는 크게 ActiveMQ와 Kafka를 직접 설치해 보고 구현을 해 보려고 합니다.
ActiveMQ
- 기업 사용 사례에 최적화된 메세지 브로커입니다. - Java Message Service(JMS) 표준을 기반으로 한 큐 기반 모델을 사용합니다.
주요 특징: 다양한 프로토콜 지원(AMQP,MQTT,STOMP), 유연한 메세지 지속성 옵션, 고급 기능 제공 메세지 우선 순위, 일정관리, 재전송 정책 등을 통해 메세지 처리 및 전달을 더 세밀하게 제어할 수 있습니다.
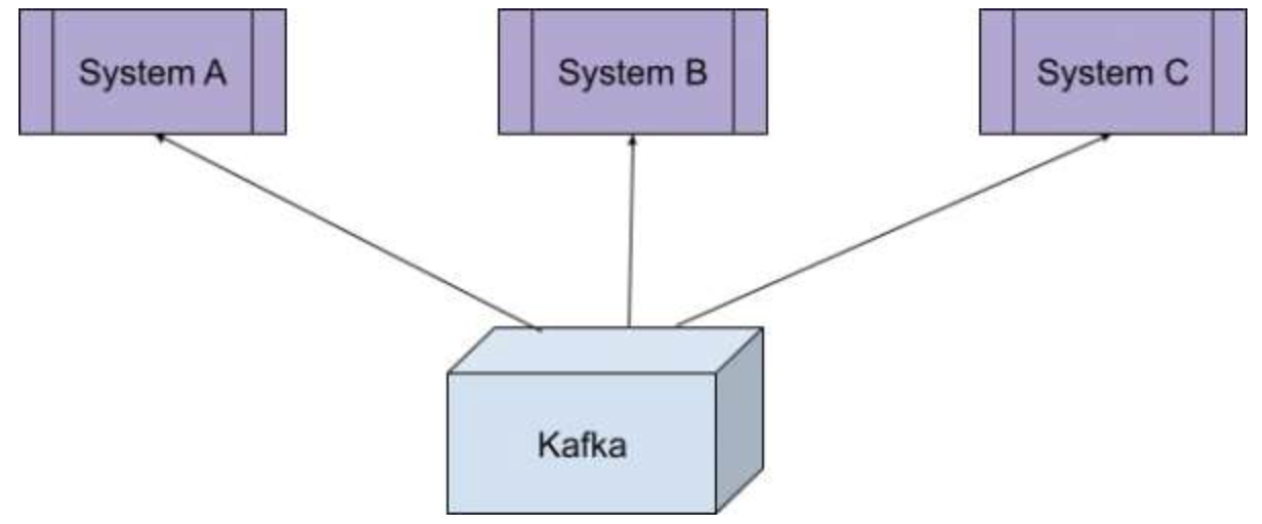
Kafka
- 확장성이 뛰어나고 내결함성이 있는 메세지 브로커 역할을 하는 오픈 소스 분산 스트리밍 플랫폼 - LinkedIn에서 개발하였으며, 높은 처리량의 실시간 데이터 스트리밍을 처리하는 데에 적합합니다.
--> 시스템에서 이벤트를 추출하는 Kafka 기반 솔루션 주요 특징: 로그 기반 저장, 수평 확장성, 이벤트에 실시간으로 반응함, 스트리밍 처리 지원 대규모 데이터 볼륨을 처리하고, 실시간 데이터 변환 및 분석이 가능합니다.
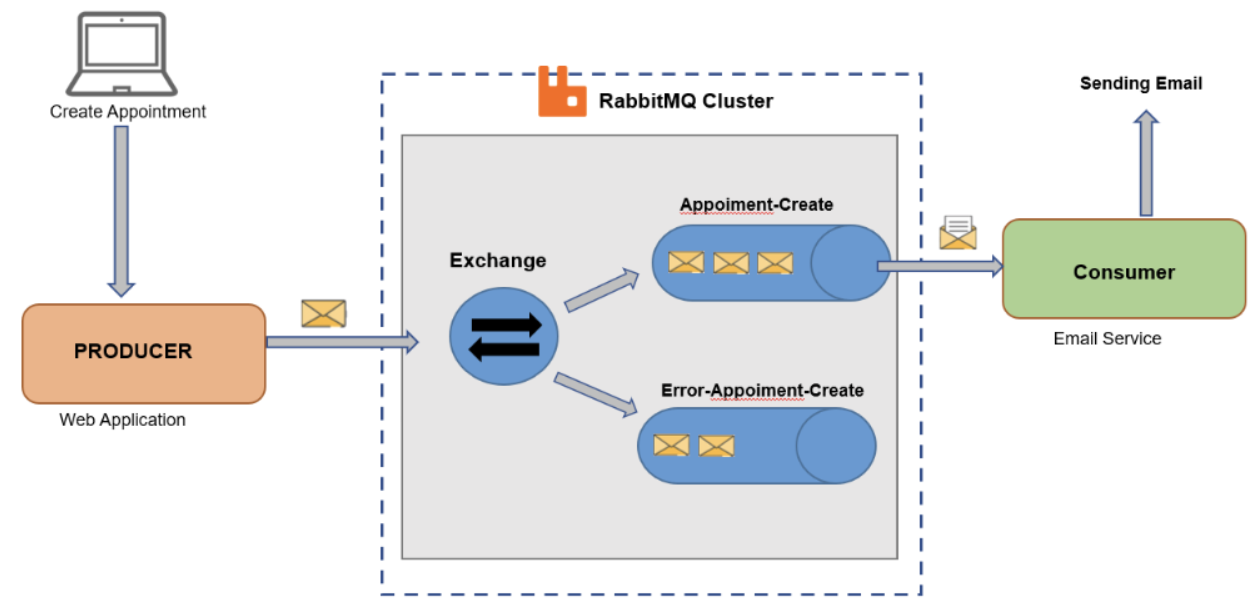
RabbitMQ
AMQP(Advanced Message Queuing Protocol)을 지원하는 오픈 소스 메세지 큐 시스템 - 다양한 메시징 패턴 및 기능을 제공합니다.
주요 특징: 다양한 프로그래밍 언어 지원, 클러스터링 및 고가용성 지원 지점 간 pub-sub 같은 다양한 메시징 패턴을 지원하므로, 유연하고 확장 가능한 통신 아키텍처가 가능합니다. 메세지 안정성과 전달을 보장하면서 복잡한 워크플로우 개발을 단순화 할 수 있습니다.
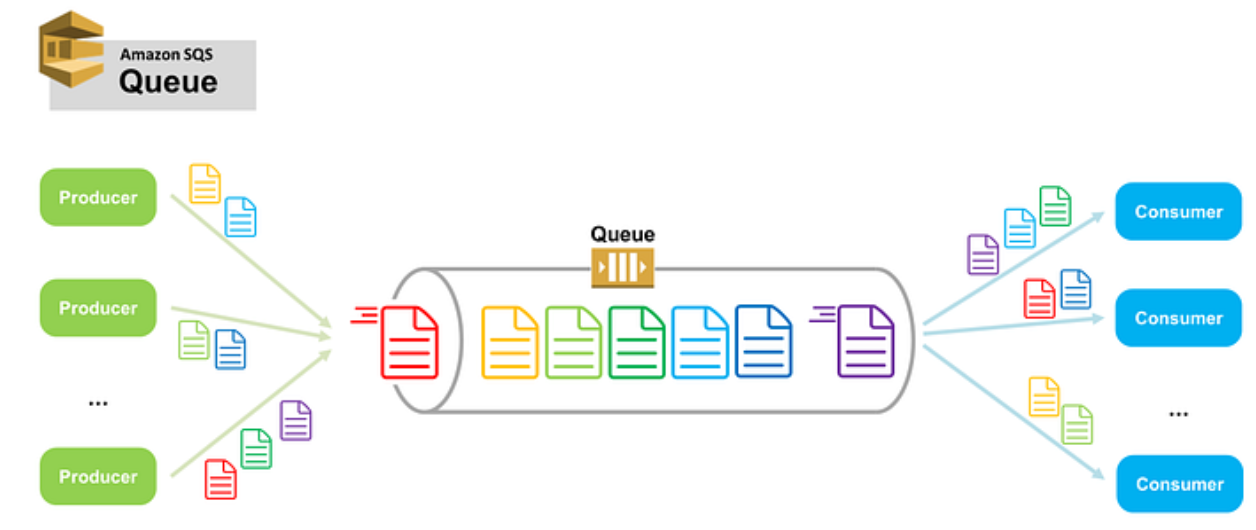
AWS SQS
AWS에서 사용되는 완전 관리형 MOM(Message Oriented Middleware)입니다. 여러 가용영역에 걸친 메시지를 저장하므로 높은 신뢰성과 수백만 메세지를 발송하고 수신할 수 있는 확장성과 처리 능력이 있습니다.
Queue에 메세지 PUT, GET에 대한 초당 처리량 제한이 없어서 거의 무제한에 가까운 처리량을 보여줍니다. - 메세지 순서에 대한 보장이 없습니다. 즉, 느슨한 FIFO 구조를 가지고 있습니다. (무조건 선입선출이 아님) - 적어도 한번은 메세지 전달이 보장되나 2회 이상 동일한 메세지가 전달될 수 있습니다. 이는 가용성을 위해 메시지가 여러 서버에 저장어 일부 서버가 사용할 수 없는 경우 메시지가 삭제되지 않고 다시 메시지를 수신할 수 있도록 설계되어져 있기 때문입니다. 그러므로 어플리케이션 설계시 멱등성을 보장할 수 있도록 설계되어야 합니다.
메세지 큐에 대해 조사를 나름대로 했는데 큐 종류들을 보니까 정말로 적재적소에 맞게 사용을 잘해야겠다는 생각이 드네요.. 직접 구현을 해 보고 상황에 맞게 데이터 전송을 진행해 봐야 좀 더 감이 잡힐 것 같습니다. ㅎㅎ 개념만 정리한 글이라 피드백이 있을지 모르겠지만 피드백은 언제나 환영입니다! 부족한 글 봐 주셔서 감사합니다... 🙇♀️
안녕하세요 효댕입니다 :D 지금은 일본으로 가는 배 위에서 글을 쓰고 있지만 이 글이 올라갈 때에는 아마 입사 전 날이 아닐까 싶네요.
사람 마음이라는 게 이직 준비를 하고 있을 땐 이것도 열심히 공부하고 저것도 공부하고 계획도 짜고 거창한 계획들이 많았는데, 막상 입사일이 정해지고 나니 출근 전 뽕을 뽑아야 한다며 어디든 돌아다니고 있습니다 ㅋㅋ 이것이 K-직장인이다....!
글또 9기에 참여하게 되면서 첫 글은 뭘 쓰는 게 좋을까 고민을 많이 했었는데요. 글또 대나무숲에 올라오는 고민들을 보면서 저 또한 겪어왔던 과정이었기에 마음에 남았던 고민들을 위주로 제 경험을 풀어 써 볼까 합니다.
이 글은 저와 같이 퇴사를 고민하시는 분들, 지금 다니는 회사에서 물경력이 될까 불안하신 분들, 진로에 대해 고민이 많으신 분들이 읽으시면 좋을 것 같습니다. 제가 물론 정답도 아니지만 저의 경험을 풀어냄으로서 이런 삶도 있구나~ 하고 가볍게 읽어주시면 될 것 같아요 ㅎㅎ
슬랙에 올린 저의 자기소개입니다
📍 커리어의 시작
위의 글대로 저는 첫 커리어를 스타트업에서 시작했는데요. 일반 스타트업도 아니라 무려 의료 스타트업이었습니다. 조금은 남들과는 다르게 색다른 경험을 했다고 볼 수도 있을 것 같아요.
저는 사실 부산을 떠나고 싶지 않다는 욕심이 좀 있어서 부산을 위주로 회사를 찾아 보게 되었고 그때까지만 해도 네트워킹이나 기술 트렌드에 관련한 의식 자체가 없었던 시기라 아 재미있겠는데? 하면 뛰어들어 보려고 했던 것 같아요. 그러던 중에 저의 첫 회사에서 면접을 보게 되었고 일단 의료 분야라는 경험하기 힘든 분야를 경험해 볼 수 있다는 것이 저의 마음을 이끌었고, 대표님과 함께 회사의 방향성에 대해 이야기해 보았을 때 도전을 많이 해 볼 수 있을 거라고 생각이 들어 합류를 하게 되었습니다.
졸업 당시 저의 주력 분야는 영상처리였지만 회사에 들어가서 웹도 만지게 되고 데이터도 다루게 되고 Dicom이라는 의료 영상에 대한 학습도 하고 어떻게 보면 여러 분야에 대해 도전할 수 있게 도와준(?) 회사에게 감사해야 할 것 같기도 합니다......
📍 선임의 부재, 갈팡질팡하는 기획, 방대한 분야의 프로젝트, 내가 여기에 계속 시간을 투자해도 되는 걸까......?
입사 당시 개발자는 저와 유니티 개발자 두 명만 있었고 개발 팀장님은 PM을 위주로 담당하셨기 때문에 전반적인 설계는 팀장님과 대표님이 하셨고 개발은 각자 개발자들이 하게 되었는데요. 제가 받은 설계 문서는 개발 아키텍처의 설계 문서가 아니라 기획 전반의 설계 문서였습니다. 그래서 그 문서를 보고 제가 어떤 식으로 개발을 해야 할지 생각을 하고 아키텍처를 설계하고, 프레임워크를 선택하고, 막히는 부분이 있으면 구글링을 하거나 주변 개발자 커뮤니티나 오픈채팅을 전전하며 의견을 묻고 참고해서 결과물을 만들고는 했어요 😅
지금 생각하면 비즈니스 아키텍처를 설계하실 수 있는 분이 한 분이라도 계셨다면 좋지 않았을까...... 하는 생각이 들긴 했습니다. 당시에도 요청을 드렸었지만 기존에 있는 자원들로 진행을 해 보자는 말에 어차피 내가 해야 하는 일이라면 즐기자 그래 찾아보자 해 보자 하면서 달려들었던 기억이 있네요.
회사 업무가 너무 많거나 본인에게 너무 많이 쏠린다 싶으면 언질이라도 한번 해 보는 것도 추천드립니다. 저 같은 경우는...... 그렇게 말해도 팀장님이 파이팅 소리만 해 주셨지 어차피 제가 해야만 하는 일이었어서 안 좋은 생각보다는 그래 이렇게 하면 내가 더 좋은 거지 경험 쌓는 거지 하면서 했었던 것 같아요. (피하지 못 하면 즐겨라.... 🤣)
시행착오를 참 많이 겪었었어요 ㅋㅋ 그렇게 맨땅에 헤딩하면서 얻은 것들도 많았어서 그때 실시간으로 좀 기록을 해 두었다면 더 성장할 수 있었을 텐데... 하는 후회가 조금 들기도 합니다. 하여! 지금부터라도 열심히 기록해 보려구요.
제가 담당한 프로젝트의 목록은 다음과 같습니다
1️⃣의료 데이터 분석 플랫폼(오픈소스) 운영 및 유지보수 2️⃣ 의료 데이터 ETL 및 데이터 베이스 관리 3️⃣ 클라우드 운영 4️⃣ 국가 과제 관련 웹 개발 프로젝트 5️⃣의료 영상(Dicom) 기반 라벨링 프로그램 개발 6️⃣ Dicom 분석 및 AI 모델 개발 7️⃣ 회사 자체 서비스 기획 및 설계, 개발
재직하고 1년이 넘어가던 시점에 제가 맡게 된 프로젝트가 꽤 많아졌습니다. 2명의 개발자를 더 채용하기도 했고요. 일을 하면서도 재미있는 프로젝트가 있었고, 의무감으로 그냥 하는 프로젝트도 있었지만 가장 제 마음을 흔들어 놓았던 것은 7️⃣번이었습니다. 1️⃣~ 6️⃣ 번은 사실 7️⃣번을 위해 진행한 프로젝트라도 봐도 무방할 정도로 서비스를 위해서 다져놓고 있는 발판들이었거든요.
저는 서비스를 만들고 싶었고 실제 유저와 소통하고 싶었으며 들어오는 피드백을 받으면서 성장해 가는 회사를 꿈꿨는데 계속 무산이 되었습니다. 개발을 시작도 해 보지도 않고 기획이 엎어져가는 모습에 지치기도 했고 의미를 잃어가고 의지가 없어지더라구요. 또 개발자가 늘어나면서 협업의 여지가 있었으나 협업을 하는 게 아니라 1인 1프로젝트 식으로 담당을 했기 때문에 협업도 잘 하지 못했어요. 거기다 이외의 일들이 꽤 힘에 부치고 힘들었어도 서비스 개발은 시작도 안 했으니 발전의 여지가 있다고 판단을 했었는데 점점 흐지부지되는 걸 보면서 여기서 더 이상 경력을 쌓으면 시간 낭비일 것 같다는 생각이 들면서 퇴사를 결심했고, 그로부터 3개월 뒤 회사를 정리하고 나오게 되었습니다. 아마 제가 조금이라도 서비스에 기여를 할 수 있는 부분이 있었다면 전 퇴사를 하지 않았을 것 같아요.
📍 이직을 하지 않고 퇴사를 결심하게 된 이유 feat. 잘 퇴사하는 법
퇴사를 결심했을 때 당장 이직을 생각해 보지 않은 것은 아니나 퇴사 준비를 하면서 인수인계 겸 이력을 정리하는데 스스로도 성에 안 차더라고요. 상대적으로 컷이 높아진 신입 개발자의 능력이라던지, 회사에서 바라는 경력자들의 경험이 저와 부합하는 게 없었습니다. 그리고 워낙 많은 분야를 얕게 진행했다 보니 백엔드로 직무 이직을 할지, 데이터 엔지니어로 이직을 할지, 데브옵스로 이직을 할지 너무 고민이 되었어요. 분야의 전문성이 떨어졌다고 느꼈기 때문에..... 경력이 햇수로 3년이 되어 가는 입장에서 다음 회사를 잘못 갔다가는 똑같은 실수를 반복할 것 같아서 정말 조심에 조심을 가해서 섣부르게 움직이지 말자는 것이 저의 다짐이었습니다.
휴학도 하지 않고 스트레이트로 달려와 일을 하고, 지금 이 시기가 제가 쉬면서 나를 알아가고 삶에 대한 정답을 찾아가고 공부를 할 수 있는 시기라고 생각했기 때문에 과감하게 퇴사를 결심하게 되었습니다.
두려움은 솔직히 없었어요. 저는 제가 누구보다 잘 헤쳐나갈 거라고 믿고 있었거든요 ㅋㅋㅋ 그리고 실제로 정말 잘 놀고 잘 헤쳐나갔고, 저와 더 친해지는 시간을 가지면서 거의 득도의 경지에 오른 경험을 했습니다. 퇴사를 두려워하지 마세요! 하지만 통장 사정을 잘 보면서 퇴사를 고민하시길 바랍니다...... 저는 그 계산까지 다 고려하고 퇴사를 했답니다.
건강한 퇴사를 하는 게 좋은 것 같아요. 나의 현실을 냉정하게 객관적으로 보면서 지금 퇴사해도 되는지, 안 되는지를 판단하고 지금 재직하고 있는 회사에서 발전의 여지가 일말이라도 있다면 조금은 존버하시고 개인 이력서를 더 다듬어 보시길 바랍니다. 저는 퇴사 전에 그렇게 하지 못해서 그게 제일 후회가 되긴 했어요. 기록을 잘하는 사람이 아니었어서 기록에 대한 아쉬움이 항상 남아있었습니다. 기록을 하게 되면 부족한 점이 보여서 그걸 스스로 더 보완할 수 있는 보충제가 되더라구요.
📍 퇴사 후 마인드셋 feat. 무기력할 때 대처법
막상 퇴사를 하고 이직 준비를 하고, 공부를 해 보니 취준생, 수험생으로 돌아간 기분이었습니다. 어떻게 보면 저는 취준생 시기를 거치지 않고 졸업도 전에 입사를 했기 때문에 정말 제대로 회사 취업을 준비한 건 이번이 처음이었는데요. 생각보다 이게 혼자 준비를 하면서 불안함도 많아지고 스스로에 대한 믿음도 떨어지고 그렇더라구요.
저는 그럴 때마다 사람들을 많이 만나고 다녔어요. 정말 추천드립니다. 개발 관련 네트워킹으로 사람들을 만나는 것이 가장 좋지만 그게 아니어도 좋아요. 저는 어떤 독서 모임에 나갔었는데 거기서 정말 다양한 사람들을 만나면서 각자 삶을 대하는 자세를 들으면서 내가 삶을 대하는 방식에 대해 생각도 많이 하게 되고, 이렇게도 삶을 꾸려나갈 수가 있구나 하는 시야들이 보였어요. 하나 예를 들자면 아, 회사가 인생의 전부는 아니구나 이런 생각도 들었었거든요. 정말 많은 용기와 힘을 얻게 됩니다. 불안하다면 혼자 고민하지 마시고 고민 상담도 많이 하시고 사람들도 많이 만나 보세요!
그리고 면접에 대해서 하나 말씀드리고 싶은 건, 저는 위에서 말했듯이 연차에 부합하지 않는 실력이라 생각해서 준비가 다 될 때까지 이력서를 넣지 않겠다는 생각이었습니다. 사실 자신이 없기도 했고요..... 하지만 그렇게 이직을 준비하다 보면 끝이 안 보입니다. 혼자 준비하면 부족한 부분밖에 안 보이거든요. 이건 이직 준비가 아니라 신입 취업 준비도 마찬가지일 것 같아요. 떨어지더라도 면접을 정말 많이 보면서 내가 어느 부분만 조금 더 채우면 될지 계속 피드백을 들으면 길이 보입니다. 미움받을 용기라는 책이 있잖아요. 저희는 면접에서 깨질 용기가 필요합니다 ㅋㅋㅋ 깨져도 일단 가는 겁니다. 그렇게 부딪혀야 멘탈도 강해지고 실력도 쌓아지고 용기가 생겨요. 조급하게 생각하지 마시고 가볍게라도 이력서 넣으면서 본인의 위치를 객관적으로 판단해 보세요. (저는 많이 놀아서 솔직히 개발 실력적으로 그렇게 대단하지 않은...) 그렇게 해서 진짜 가고 싶은 회사는 그런 일들을 다 겪은 후에 마지막으로 준비가 되었다고 생각했을 때 넣어 보는 겁니다. 저는 아직 넣지 않았습니다. 몇 년이 걸릴 것 같아서요 ㅋㅋ 언젠가 때가 올 때를 기다리며......
📍 이직 완료. 회사를 고른 기준이 있다면?
면접을 보면서 제가 염두에 둔 마음 속의 기준들이 몇 가지 있었습니다.
공부를 하면서 백엔드도 공부해 보고, 데이터 엔지니어도 공부를 했는데 저는 데이터 쪽이 재미있더라구요. 그래서 데이터 엔지니어 위주로 공고를 찾았습니다.
1. 회사의 서비스가 명확할 것 2. 나의 직무가 명확할 것 3. 재택 가능 or 부산 기업 4. 나의 성장 가능성과 회사의 성장 가능성이 함께 우상향을 그릴 수 있는지 5. 재미있는 거 하고 싶다
이것이 저의 이번 이직의 기준이었습니다.
최종 합격한 회사는 ETL/BI의 직무로 저에게 바라는 것이 명확하였고 내부 사정을 들어보니 레거시 덩어리를 클라우드로 이전할 거라는 이야기를 듣고 재미있을 것 같다는 느낌이 확 들어왔습니다. 고민도 하지 않고 제가 경험할 게 많을 것 같다는 생각이 들어서 면접관 분들과 기술 이야기만 하다가 면접이 끝나버렸네요 ㅎㅎ 이전과는 다르게 저도 성장했고 같이 고민할 팀원들도 많다고 하니 아무래도 부산에서는 이런 경험하기가 쉽지는 않을 것 같아서 꽤나 기대가 됩니다.
📍 글을 끝내며
이렇게 글을 쓰는 게 정말 오랜만이라, 적고 싶은 말이 많았었는데 두서 없이 써내린 것 같기도 하고... 나름 가독성 있게 쓰고 싶은데 문단을 잘 나눴는지 괜찮은지 당장은 영 어렵네요 ㅋㅋㅋ
제 글을 읽고 이야기를 더 나눠보고 싶으신 분들이나 고민 상담하고 싶으신 분들 있다면 얼마든지 커피챗 연락 주시면 바아로 들어가겠습니다 🐥